Image Processing Reference
In-Depth Information
3.4 HMM for Expression Modeling and Recognition
To decode the depth information-based time-sequential facial expression features, discrete
HMMs are employed. HMMs have been applied extensively to solve a large number of com-
An HMM is a collection of states where each state is characterized by transition and symbol
observation probabilities. A basic HMM can be expressed as
H
= {
S
,
π
,
R
,
B
} where
S
de-
notes possible states,
π
the initial probability of the states,
R
the transition probability matrix
between hidden states, and
B
observation symbols' probability from every state. If the number
of activities is
N
then there will be a dictionary (
H
1
,
H
2
, …,
H
N
) of
N
trained models. We used
the structure and transition probabilities of a sad HMM after training.
FIGURE 8
A HMM transition probabilities for sad expression after training.
To test a facial expression video for recognition, the obtained observation sequence
O
from
the corresponding depth image sequence is used to determine the proper model by highest
likelihood
L
computation of all
N
trained expression HMMs as follows:
(9)
4 Experiments and results
The FER database was built for six expressions: namely Surprise, Sad, Happy, Disgust, Anger,
and Fear. Each expression video clip was of variable length and each expression in each video
starts and ends with neutral expression. A total of 20 sequences from each expression were
used to build the feature space. To train and test each facial expression model, 20 and 40 image
sequences were applied, respectively.
The average recognition rate using PCA on depth faces is 62.50% as shown in
Table 1
. Then,
we applied LDA on PCA features and obtained 65.83% average recognition rate as shown in
Table 2
. As PCA-based global features showed poor recognition performance, we tried ICA-
based local features for FER and obtained 83.33% average recognition rate as reported in
Table
3
. To improve ICA features, we applied LDA on the ICA features and as shown in
Table 4
, the
average recognition rate utilizing ICA representation on the depth facial expression images is
83.50%, which is higher than that of depth face-based FER applying PCA-based features.

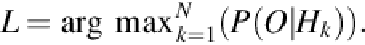
Search WWH ::

Custom Search