Image Processing Reference
In-Depth Information
detection to extract key frames. This method depends on kind of videos, and length of videos.
Although this method is not the best method, it is a good idea that we can use in our system.
In ICPR 2012 conference, there were six systems submited to. To describe their cooking
FAST detector and CHOG3D descriptor, and combined with hand motion feature which was
extracted from depth images. In that research, they achieved some spectacular results. The av-
erage accuracy for action recognition in their experiment is 50.6% in case of using depth local
feature and 53.0% when they used local feature. Then, when they combine these kinds of fea-
ture, the accuracy is achieved 57.1%.
The winning entry was by a team from Chukyo University, Japan. Their method uses heur-
istic approach using image features with some modifications. Then, in postprocessing step,
they use some methods to avoid unnatural labeling results. Their result proved that this ap-
proach is more effective than other approaches in practical use. Besides, the other recogni-
tion systems from other teams are also interesting. They use motion history image feature,
spatio-temporal interest point description feature, trajectories feature, and context informa-
tion. Moreover, they use one-versus-all linear Support Vector Machine (SVM) classifier as an
action model. In postprocessing, they apply 1D Markov random field on the predicted class
labels.
According to these methods, we could conclude that an effective action recognition method
usually uses some diferent features and combines them to achieve the beter result. Besides,
the information such as context information and cooking action sequence are also important
for improving the accuracy of our method.
3 Our Method
3.1 Our Recognition System Overview
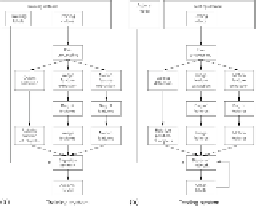
Below there are two diagrams, which, respectively, shows training framework and testing
framework of our recognition system. As depicted in
Figure 1
, the main steps in these frame-
works are the same.
FIGURE 1
Diagrams to describe our method's systems (a) is our training system and (b) is
our testing system.
First of all, the input videos are preprocessed through some minor-steps including calibra-
tions, segmentation, objects and human detection, and hands detection. Next, some features
are extracted from both depth images and color images. According to basic action recognition
methods, they extract motion features in the videos and perform discriminative analysis for
action recognition. For cooking action recognition problem, however, some actions cannot be
described by using a motion feature alone. Hence, we propose to extract both human's motion
feature and image features from cooking video.
Search WWH ::

Custom Search