Image Processing Reference
In-Depth Information
carry more anecdotes than a short LC could possibly do. For example, it is obvious that “[
]” is a beter anecdote than its substring “[
]” or “[
]” or
“[ ].” To enhance the semantics of candidate anecdotes, we will take a further concat-
enation process as the last step to finalize the CLCP.
3.2.4 Step 4: Execute postprocessing
In the final step, significant words are determined by observing the information mutually
shared by two-overlapped LCs using the following significance estimation (SE) function as
(3)
(3)
where
fi
denotes the LC
fi
to be estimated, that is,
fi
=
fi
fi
·
fi
2
, …,
fi
n
;
a
and
b
represent the two longest
compound substrings of LCi
fi
with the length
n
− 1, that is,
a
=
fi
fi
·
fi
2
, …,
fi
n
− 1
and
b
=
fi
2
·
fi
3
, …,
fi
n
.
The
fi
a
,
fi
b
and
fi
fi
are the frequencies of
a
,
b
, and
fi
, respectively. In the above example, the term
fi
, “[
]” (Yu Chang case), shall gain the SE value of 0.83 based on its frequency 5 and the
frequency 6 of its substring
a
, “[
]” (Yu Chang), as well as the frequency 5 of the other
substring “[
]” (Chang case). In this case, we will retain term
fi
“[
]” and its
substring
a
“[
]” because the frequency of “[
]” is less than “[
]” in-
dicating “[
]” carries useful meanings. Likewise, we will discard the substring
b
“[
]” because both terms have the same frequency indicating the long term “[
]”
can replace its substring “[
].” As stated above, since
fi
fi
<
fi
a
, we retain both terms, and
discard “[
]” because
fi
fi
=
fi
b
.
3.2.5 Term weighting
It is suggested that the most significant content description often appears in the title and the
irst paragraph. In addition, word frequency and word length are also accepted as the indic-
ators of term discrimination value in a document. Given a word LCi,
fi
, the term weighting al-
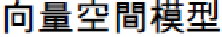





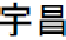



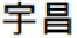







Search WWH ::

Custom Search