Image Processing Reference
In-Depth Information
on the enhancement of annotation quality, the aforementioned approaches tend to assign the
same annotation to all the images in the same cluster thereafter they suffered the lack of cus-
tomized annotation for each image.
2.2 Keyword Extraction
In the field of information retrieval, keyword extraction plays a key role in summarization,
text clustering/classification, and so on. It aims at extracting keywords that represents the text
theme. One of the most prominent problems in processing Chinese texts is the identiication
of valid words in a sentence, since there are no delimiters to separate words from characters
in a sentence. Therefore, identifying words/phrases is difficult because of segmentation ambi-
guities and the frequent occurrences of newly formed words.
In general, Chinese texts can be parsed using dictionary lookup, statistical, or hybrid ap-
proaches [
15
]. The dictionary lookup approach identifies keywords of a string by mapping
well-established
corpus.
For
example,
the
Chinese
string
“
” (Ying-wen Tsai went to Taipei prison to vis-
it Shui-bian Chen and talk for an hour) will be parsed as: “[
],” “[
],” “[
],” “[ ],” “[ ],” and “[ ]” by a well-known dictionary-based CKIP
(Chinese Knowledge and Information Processing) segmentation system in Taiwan. This meth-
od is very efficient while it fails to identify newly formed or out-of-the-vocabulary words and
it is also blamed for the triviality of the extracted words.
Since there is no delimiters to separate words from Chinese string except for the usage of
quotation marks in special occasion, word segmentation is a challenge without the aid of dic-
tionary. The statistical technique extracts elements by using
n
-gram (bi-gram, tri-gram, etc.)
computation for the input string. This method relies on the frequency of each segmented token
and a threshold to determine the validity of the token. The above string through
n
-gram seg-
mentation will produce: “[
], [
], [
], [
], [
], [
],
[
], [
], [
], [
], [
]”; “[
], [
], …, [
]” and so on. The application of this method has the benefit of corpus-free and the
capability of extracting newly formed or out-of-the-vocabulary words while at the expense of
huge computations and the follow-up filtering eforts.
method conducts dictionary mapping to process the major task of word extraction and handle
the leftovers through
n
-gram computation, which significantly reduces the amount of terms
under processing and takes care both the quality of term segmentation and the identi-fication.
Since the most important task of annotation is to identify the most informative parts of a text
comparatively with the rest. Consequently, a good text segmentation shall help in this identi-
ication. In the IR theory, the representation of documents is based on the vector space model
[
21
]
: A document is a vector of weighted words belonging to a vocabulary
V
:
d
= {
w
1
, …,
w
|
v
|
}.
Each
w
v
is such that 0 ≤
w
v
≤ 1 and represents how much the term
t
n
contributes to the se-




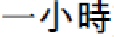




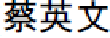
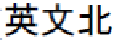
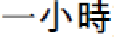
Search WWH ::

Custom Search