Image Processing Reference
In-Depth Information
important field of study. From this point of view, event boundary detection, temporal video
segmentation, cut detection, etc. are similar concepts dealing with this problem.
Again, textual and audio features together with visual features are important sources of in-
formation for temporal video segmentation likewise in temporal video segment representa-
tion. Our main concern about automaticity and dependency of textual features to manual cre-
ation also continues here. Therefore, visual features' domination proceeds in this problem, too.
Regarding this domination, detecting the cuts between video scenes using visual features is
an important problem. Optical flow is the key concept behaving as an operator inspiring from
the representation proposed for action recognition in this study. The fundamental idea, here,
is that some sort of change in optical flow character determines the cuts. In detail, the hypo-
thesis is that the difference of intensity values between the pixels (mapped with optical flow
vectors) of consecutive frames changes at the cut points. Calculated optical flow vectors in the
irst phase, video segment representation, can also be used here as building block features op-
erating on pixel difference calculations to represent scene changes. This yields to a decrease in
the computational complexity because of the fact that the feature base, optical flow vectors, is
same and singularly calculated for both phases.
Estimated optical flow vectors for each frame in the previous part can be used. The equation
R
= [
S
(
V
),
Φ
] giving the optical flow-based generic representation, defined in
Section 5
,
can be
handled and adapted to cut detection. From this point of view,
Φ
is the operator defining the
relations between the optical flow vectors
S
(
V
) and giving their meaning for representing cuts.
In our adaptation of the above representation to temporal video segmentation—cut detec-
tion, the description of
Φ
is important. In order to make this description, the parameters used
in the definition should be described.
7 Experiments and results
Temporal segment classification for action recognition uses the vector representation pro-
sian radial basis function—using standard deviation σ for two feature vectors
x
i
,
x
j
- —is selec-
ted as SVM kernel.
(21)
video segments composed of human actions from 32 movies. Each segment is labeled with
one or more of 8 action classes:
AnswerPhone, GetOutCar, HandShake, HugPerson, Kiss, SitDown,
SitUp,
and
StandUp.
While, the test set is obtained from 20 movies, training set is obtained
from 12 other movies different from those in the test set. The training set contains 219 video
segments and the test set contains 211 samples with manually created labels.
After the optical flows are estimated, the calculations for constructing feature vectors are
carried out accordingly and feature vectors are obtained for the test data. The number of an-
as discussed in this section, was determined experimentally.
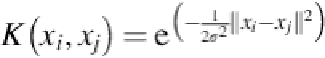
Search WWH ::

Custom Search