Image Processing Reference
In-Depth Information
tiprocessors. CUDA uses a single instruction multiple thread architecture that enables us to
write thread-level parallel code.
CUDA also features several high-bandwidth memory spaces to meet the performance re-
quirements of a program. For example, Global memory is memory accessed by the host com-
puter and by the GPU. Other memory types are only accessible by the kernels and reside with-
in the chip and provide a much lower latency: a read-only constant memory, shared memory
(which is private for each block of threads only), a texture cache and, finally, a two-level cache
that is used to speed up accesses to the global memory. Coordination between threads within
a kernel is achieved through synchronization barriers. However, as thread blocks run inde-
pendently from all others, their scope is limited to the threads within the thread block. CPU-
based techniques can be used to synchronize multiple kernels.
Generally, in a CUDA program, data are copied from the host memory to the GPU memory
across the PCI bus. Once in the GPU memory, data are processed by kernels (functions that
run in the GPU), and upon completion of a task the data need to be copied back to the host
memory. Newer GPUs support host page-locked memory where host memory can be accessed
directly by kernels, but that reduces the available memory to the rest of the applications run-
ning on the host computer. On the other hand, this eliminates the time needed to copy back
and forth data from host to GPU memory and vice versa. Additionally, for image generation
and manipulation application, we can use the interoperability functionality of OpenGL with
CUDA to improve further the performance of an application. This is because we can render an
image directly on the graphics card and avoid copying the image data from the host to GPU,
and back, for each frame.
3 Parallel algorithms for image processing
Spatial domain filtering (or image processing and manipulation in the spatial domain) can be
implemented using CUDA where each pixel can be processed independently and in parallel.
The spatial domain is a plane where a digital image is defined by the spatial coordinates of
its pixels. Another domain considered in image processing is the frequency domain where a
digital image is defined by its decomposition into spatial frequencies participating in its form-
ation. Many image-processing operations, particularly spatial domain filtering, are reduced to
Let
S
xy
be the set of coordinates of a neighborhood (normally a 3 × 3 or 5 × 5 matrix) that is
centered on an arbitrary pixel (
x
,
y
) of an image
f
.
Processing a local neighborhood generates a pixel (
x
,
y
) in the output image
g
. The intensity
of the generated pixel value is determined by a specific operation involving the pixel in the
the following expression:
where
f
(
x
,
y
) is the intensity value of the pixel (
x
,
y
) of the input image,
g
(
x
,
y
) is the intensity
value of the pixel (
x
,
y
) of the output image, and
T
is an operator defined on a local neighbor-
hood of the pixel with coordinates (
x
,
y
), shown in
Figure 1
.
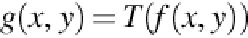
Search WWH ::

Custom Search