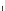Information Technology Reference
In-Depth Information
Network Samples
Network Samples
Network Samples
V:285 − E:432
V:2927 − E:7626
V:3886 − E:34092
Random Walk
Forest Fire
Random Walk
Forest Fire
Random Walk
Forest Fire
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
%Vertices sampled
%Vertices sampled
%Vertices sampled
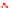
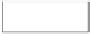
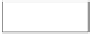
Fig. 2
Network Samples by Different Sampling Methods and Experiment Configurations.
“V” and “E” in the subtitles denote the number of vertices and number of edges respectively
different ego networks. Figure 2 illustrates how the resulted networks vary from
sample to sample, given different edge sample size configuration, by plotting the
percent of edge sampled against percent of vertices sampled for three different net-
works. We can see the points produced by the RE method produced were clustered
around the selected sample size points; while the points yielded by the FF method
were more spread out. The FF method sampled more vertices than the RE method
when required edge sample size is huge. The RE method more often stopped before
reaching the targeted sample size when the required sample size was relatively high.
5.1
Performance Measure
One way of evaluating how good the samples are is to see how good they are in
estimating degree distributions. [11] shows that predictions for typical vertex-vertex
distance, clustering coefficients and vertex degree based on only degree distributions
agree well with empirical data. Figure 3 shows that the eight ego networks selected
for our study have different degree distributions: some follow power law and some
do not.
The plot on the left in Figure 4 illustrates the estimated degree distributions by
the two methods and the true distribution using one of the eight ego networks with
a sample size of 5% of the total network. We can see that even though the sampled
edges are only about 5% of the total, the degree distribution estimations are not
bad for small degrees (
50). This finding is in line with the study by [9]. They
show that only the maximal degrees significantly depend on the sample size and the
average degree is roughly constant. The plot on right shows the estimations of the
CC distribution conditional on node degree. The dots represent the conditional CC's
and the curves are the spline fits. Both methods underestimate the conditional CC
of the high degree nodes.
<