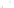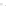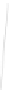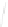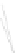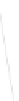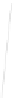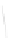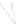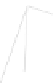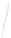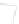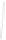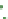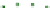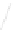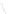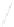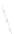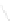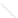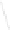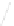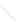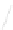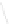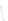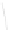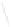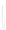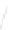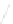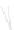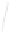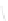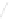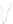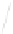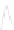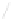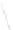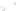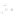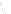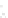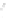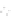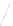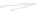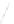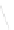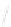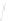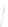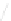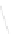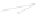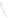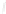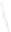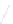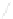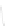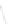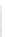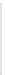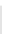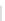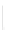Information Technology Reference
In-Depth Information
Blog A
Blog A
Blog A
Blog
B
Blog
B
Blog B
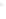
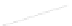
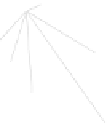
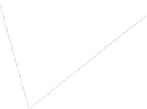
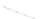
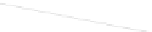
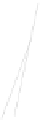
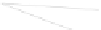
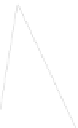
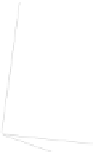
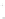
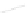
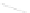
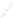
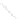
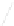
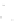
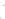
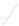
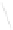
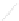
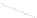
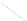
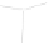
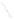
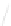
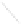
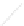
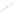
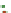
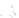
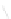
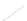
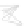
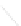
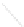
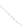
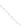
Fig. 1
Sample ego-networks for two web sites, Blog A and Blog B, using the random burn
method
4
Network Measures
The goal of this study is to understand if a random network, generated using the best
known models of social network growth, can be measured on a node-by-node basis
with common network metrics, and have those measurements be similarly captured
using our process of creating ego-networks.
There are various centrality measures for finding the important (central) nodes
(see [18] for a recent discussion). In this study we utilize the degree distribution
and the clustering coefficient to capture the structure of the network. The degree of
a node in the network is the number of adjacent edges of the node. The clustering
coefficient (CC) measures the probability that the adjacent nodes of a node are con-
nected. It is sometimes also called transitivity. High CC is an indication of a small
world, i.e., most nodes can be reached from every other by a small number of steps.
5
Empirical Experiments
We evaluate our approach to find if it can preserve the real network structure and to
determine how big of a sample size is needed to achieve good accuracy. The evalua-
tion is done using the Stanford-Berkeley Web network crawled by [7] in December
2002. It contains 685,230 nodes and 8,006,115 links. The connectivity statistics of
this network are similar to the results of [2], which shows that the link structure at
the level of hosts and domains also follows a inverse power law distribution.