Information Technology Reference
In-Depth Information
Hence the corpus becomes a matrix
m
x
n
, which have
m
rows and
n
cols with
respect to
m
document and
n
terms.
D
i
is called document vector.
The essence of document classification is to use supervised learning algorithms
in order to classify corpus into groups of documents; each group is labeled. In this
chapter we apply two methods namely support vector machine, decision tree and
neural network for document classification.
2 Document Classification Based on Support Vector Machine
2.1 Support Vector Machine
Support vector machine (SVM) [Cristianini, Shawe-Taylor 2000] is a supervised
learning algorithm for classification and regression. Given a set of
n-
dimensional
vectors in vector space, SVM finds the separating hyper-plane that splits vector
space into sub-set of vector; each separated sub-set (so-called data set) is assigned
one class. There is the constraint for this separating hyper-plane: “it must
maximize the margin between two sub-sets”.
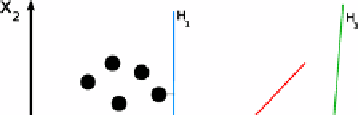
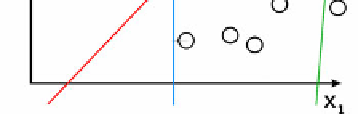
Fig. 1
Separating hyper-planes
Suppose we have some
n-
dimensional vectors; each of them belongs to one of
two classes. We can find many
n-1
dimensional hyper-planes that classify such
vectors but there is only one hyper-plane that maximizes the margin between two
classes. In other words, the nearest between a point in one side of this hyper-plane
and other side of this hyper-plane is maximized. Such hyper-plane is called
maximum-margin hyper-plane and it is considered as maximum-margin classifier.
Let {
X
1
, X
2
,…, X
n
} be the training set of vectors and let
y
i
= {1, -1}be the class
label of vector
X
i
. It is necessary to determine the maximum-margin hyper-plane
that separates vectors belonging to
y
i
=1 from vectors belonging to
y
i
= -1. This
hyper-plane is written as the set of point satisfying: