Database Reference
In-Depth Information
example, but that would be inecient. In addition, it is not mandatory that
all participants are directly interconnected (either by network or by protocol)
and transfers may have to be scheduled to make the whole operations possible
(destinations of completed transfers being considered as potential sources).
The library also makes possible to delegate transfers on all GridRPC servers
that offers some library specific service. Hence transfers can be distributed over
nodes to reduce the bandwidth impact, and/or to try to reduce the transfer
operation completion date for example.
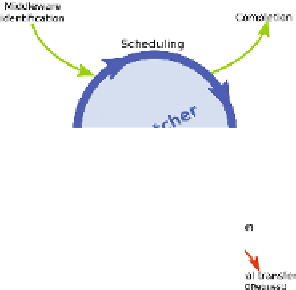
In order to build a schedule in our implementation (made by the dispatcher,
Fig 3), we list the nodes that can participate to a transfer operation: To our bene-
fit, since the library contains middleware modules, it can also rely on underlying
GridRPC middleware to potentially add relay servers to [remotely] distribute
the transfer load or a part of it. To discover those middleware nodes, the library
provides an
echo
service, that must be deployed,
i.e.,
registered in the GridRPC
server capabilities (at the moment, only middleware nodes with the
memory
pro-
tocol available are considered. If the service is not deployed, the node is simply
not considered as a possible relay).
Data Manager
Download
Upload
Middleware call
Client
Server
RAM
Data Manager
Download
Upload
Fig. 2.
Automatic transfers during a
GridRPC call
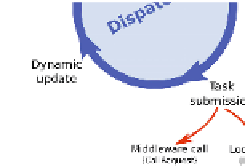
Fig. 3.
Dispatcher's cycle
Then URIs are sorted: Local, Middleware node or Storage server; and the
dispatcher uses a Round-Robin algorithm to build and launch every one-to-one
transfer according to the sorted list below: the list describes
by priority of action
,
matching one input URI to one output URI depending on their nature (Local,
Middleware or Storage), the action undertaken to manage the corresponding
transfer. As seen in Sec. 3.2, transfers at the same time are possibly limited in
number, they are monitored with an effective and su
cient semaphore mech-
anism, and a completion leads to a dynamic update of the set of input URIs.
The above algorithm loops until all transfers to ouput locations are done. In
case of failure due to an unresponsive input middleware, the middleware is not
considered anymore in the next scheduling/mapping cycle.













Search WWH ::

Custom Search