Database Reference
In-Depth Information
Moreover, it is noted that intermediate key-value pairs output from REDUCE-1 have
the descending order by the length of the list D
i
a term
k
has and then by the total
words W
i
of D
i
in each list. In this way, we want to apply our filtering methods espe-
cially for the pivot document case, with range and k-NN queries in section 5, in order
not to transfer much data over the network. As a consequence, the candidate size is
significantly decreased.
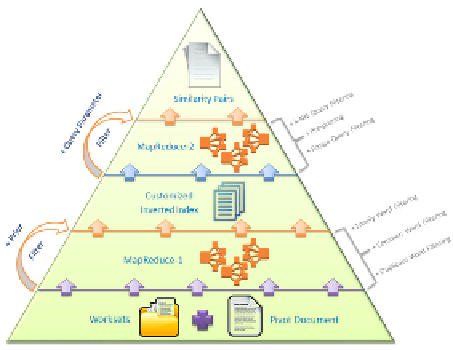
Fig. 1.
The overview scheme
The Prior Filter is applied at the MapReduce-1 operation whilst the Query Parame-
ter Filter is attached to the MapReduce-2 operation. The former consists of three sub-
filtering methods known as Duplicate Word Filtering, Common Word Filtering, and
Lonely Word Filtering. Meanwhile, the latter is composed of another three sub-
filtering named Range Query Filtering, Pre-pruning, and k-NN Query Filtering. These
filtering methods are alternatively combined to support specific similarity search sce-
narios. In general, the proposed scheme is not limited to be applied for various simi-
larity search strategies as discussed in section 5 of this paper. For simplicity, we
present how the proposed scheme at first works for pairwise document similarity
search in sub-section 5.1, and then we show how our scheme is effectively adapt itself
to other similarity search parameters in the remaining sub-sections.
Let D
i
be the i
th
document of the workset, W
i
be the total words of D
i
, n be the ac-
cumulated number of the same key, and sim(D
i
, D
j
) be the similarity score between a
document pair. The two MapReduce operations can be summarized as follows:
MAP-1:
,
@
REDUCE-1:
,
@
,
@
MAP-2:
,
@
@
@
,
REDUCE-2:
@
@
,
,
,
Search WWH ::

Custom Search