Database Reference
In-Depth Information
2.2 MapReduce
The principle of MapReduce consists of splitting the data into parts so their
process is simultaneously done. The model defines two main functions, the Map
function processes input chunks and the Reduce function processes the output
of Map tasks and outputs final results.
Computing elements can be classified into Mapper nodes, which execute Map
tasks and Reducers which execute Reduce tasks. In a first step, input data are
divided into chunks and distributed over the Mappers. Then, Mappers apply
the Map function on each chunk. The result of the execution of a Map task is
list(k,v), a list of key and value pairs. An intermediate Shue phase sorts the
map outputs, called intermediate results, according to keys so that in a second
step, each Reducer processes a set of the keys. In the Reduce phase, Reducers
apply the Reduce function to all of the values (k, list(v)) for a specific key. At
the end, all the results can be assembled and sent back to the user.
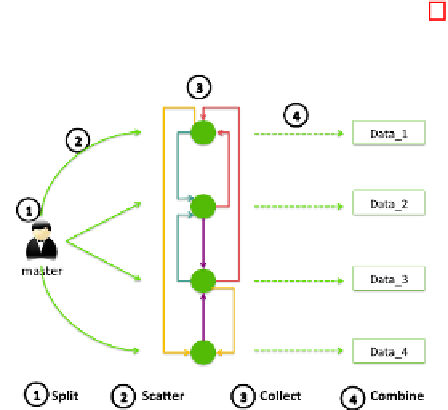
3 Our Secure MapReduce Approach Based on IDA
Our approach is composed of four phases, illustrated in Figure 1 as follows:
Fig. 1.
IDA Phases for MapReduce
3.1 Preparation Phase (Split)
Classical MapReduce master splits the input data into chunks based on the
chunk size. In our approach, we apply the IDA split routine on input data which
generates
n
chunks. A chunk
M
i
is composed of 1) a header containing the key
vector of order
i
(i.e. the
i
th
row of the key matrix), 2) a body storing the
i
th
row of the key matrix and data product. All generated chunks will be dispersed
to the mappers machines.
Search WWH ::

Custom Search