Database Reference
In-Depth Information
1
1
1
0.8
0.8
0.8
0.6
0.6
0.6
Diversified
Undiversified
0.4
0.4
0.4
0.2
0.2
0.2
0
0
0
Jaccard Cosine over big Overlap
Jaccard Cosine over big Overlap
Jaccard Cosine over big Overlap
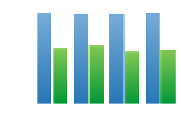
(a)
MovieLens
(b)
Flickr
(c)
LastFM
1
1
1
0.8
0.8
0.8
Usefulness (Jaccard)
xQuad (Jaccard)
MMR (Jaccard)
Jaccard
0.6
0.6
0.6
0.4
0.4
0.4
0.2
0.2
0.2
0
0
0
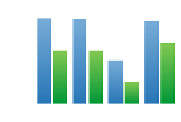
(d)
MovieLens
(e)
Flickr
(f)
LastFM
Fig. 2.
Effect on recall of diversification
Not surprisingly, diversifying the
U-Net
enables for all relevance score to sig-
nificantly increase recall. On the
MovieLens
dataset, the recall results without
diversification range between 0
.
58 and 0
.
62 while they range between 0
.
978 and
0
.
999 with diversification. On the
Flickr
dataset, the gains are slightly smaller.
Since all users share their own pictures, their profiles are very different and al-
ready diversified. Therefore, diversification has less impact on the recall. Finally,
the
LastFM
dataset recall results are up to 3.26 times higher.
In addition to improve the recall, diversified solutions enable to reduce the
variance compared to undiversified solutions. For instance, on
Flickr
,thevari-
ance decreases from 0
.
116 to 0
.
013 when using
Jaccard
. This can be explained
by the fact that in the undiversified solution, users in
U-Net
are very similar
among them. As a consequence, either all are relevant to the query, and hence
they provide a high recall; or none of them is, thus producing a low recall. Diver-
sification enables to increase coverage and therefore, it increases the probability
to answer any kind of query.
In addition, we ran these experiments with different sizes of
U-Net
and values
of
TTL
. For instance, on the
MovieLens
dataset, with a
U-Net
of size 5 and a
TTL
of 2, the recall is in average 2
.
37 times higher compared to undiversified
solutions. Indeed, without diversification, recall values are in average of 0
.
26
while they reach 0
,
61 using usefulness.
We have also compared three different diversification methods. The first is
the
usefulness
score presented in Equation 7. The second method we use is the
Maximal Marginal Relevance
,knownas
MMR
[13].
MMR
chooses users that
minimize the maximum similarity between any two users in
u
's
U-Net
. Finally,
the last method is
Explicit Query Aspect Diversification
known as
xQuad
[14].
xQuad
chooses users such that each user
v
i
in
u
's
U-Net
is similar to
u
in a
different way. For instance, suppose that
u
shares items
i
1
and
i
2
.If
v
1
is in
u
's
U-Net
and is similar to
u
because it also shares
i
1
, then,
xQuad
chooses a user
v
2
such that
v
2
is similar to
u
because it shares the item
i
2
. In this experiment,
we use
Jaccard
as the similarity measure.

























Search WWH ::

Custom Search