Information Technology Reference
In-Depth Information
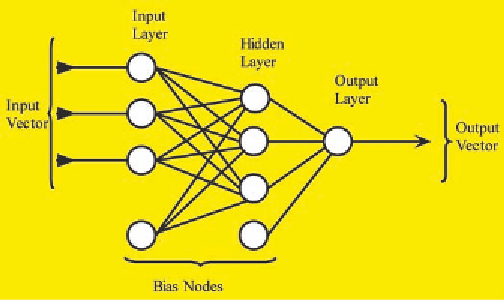
Figure 2. Diagram of a neural network
With no hidden layers, the results of a neural network analysis resemble those of regression. Each
input variable is connected to each variable in the hidden layer, and each hidden variable is connected
to each outcome variable. The hidden layers combine inputs and apply a function to predict outputs.
Hidden layers are often nonlinear.
The architecture of the neural network is used to define the model. There are two major types of
neural network used, the MLP and the GLIM. MLP, the multi-layer perceptron, is the default model. A
perceptron is a classifier that maps an input x to an output, f(x). The GLIM represents the more standard
generalized linear model discussed in detail in Chapter 3. You should compare these two models to see
the impact on the results. You can also define your own model, although this method is not recommended
for beginners.
Decision trees provide a completely different approach to classification. A decision tree develops a
series of if-then rules. Each rule assigns an observation to one segment of the tree, at which point another
if-then rule is applied. The initial segment, containing the entire data set, is the root node for the decision
tree. The final nodes are called leaves. Intermediate nodes (a node plus all its successors) form a branch
of the tree. The final leaf containing an observation is its predictive value.
Unlike neural networks and regression, decision trees do not always work with interval data. Deci-
sion trees work better with nominal outcomes that have more than two possible results and with ordinal
outcome variables. Missing values can be used in creating if-then rules. Therefore, imputation is not
required for decision trees, although you can use it when working with decision trees.
PredIctIve modelIng In sas enterPrIse mIner
For predicting a rare occurrence, one more node is added to the model in Figure 1, the sampling node
(Figure 3). This node uses all of the observations with the rare occurrence, and then takes a random
sample of the remaining data. While the sampling node can use any proportional split, we recommend a
50:50 split. Figure 4 shows how the defaults are modified in the sampling node of SAS Enterprise Miner
to make predictions. Starting a project in SAS Enterprise Miner was discussed in Chapter 1.
Rule induction is a special case of a decision tree model. Figure 3 also shows three different neural
network models and two regression models. The second regression model automatically categorizes all
Search WWH ::

Custom Search