Database Reference
In-Depth Information
Apache Hive
Just like Pig, Hive is an abstraction over MapReduce. However, the Hive interface is more
similar to SQL. This helps SQL-conversant users work with Hadoop. Hive provides a
mechanism to define a structure of the data stored in HDFS and queries it just like a rela-
tional database. The query language for Hive is called
HiveQL
.
Hive provides a very handy way to plug in custom mappers and reducers written in
MapReduce to perform advanced data processing.
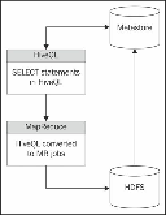
Hive usually runs on the client-side machine. Internally, it interacts directly with the job-
tracker daemon on the Hadoop cluster to create MapReduce jobs based on the HiveQL
statement provided via the Hive command-line interface. Hive maintains a metastore where
it stores all table schemas for the required files stored in HDFS. This metastore is often a
relational database system like MySQL.
The following diagram shows the high-level workings of Apache Hive:
The Hive command-line interface uses the schema available on the metastore along with
the query provided, to compute the number of MapReduce jobs that need to be executed on
the cluster. Once all the jobs are executed, the output (based on the query) is either dis-
played onto the client's terminal or is represented as an output table in Hive. The table is
nothing but a schema (structure) for the output files generated by the internal MapReduce
jobs that were spawned for the provided HiveQL.