Database Reference
In-Depth Information
Apache Sqoop
While analyzing data, data analysts often have to gather data from different sources such as
external relational databases and bring it into HDFS for processing. Also, after processing
data in Hadoop, analysts may also send the data from HDFS back to some external rela-
tional data stores. Apache Sqoop is just the tool for such requirements. Sqoop is used to
transfer data between HDFS and relational database systems such as MySQL and Oracle.
Sqoop expects the external database to define the schema for the imports to HDFS. Here,
the schema refers to metadata or the structure of the data. The importation and exportation
of data in Sqoop is done using MapReduce, thereby leveraging the robust features of
MapReduce to perform its operations.
When importing data from an external relational database, Sqoop takes the table as an in-
put, reads the table row by row, and generates output files that are placed in HDFS. The
Sqoop import runs in a parallel model (MapReduce), generating several output files for a
single input table.
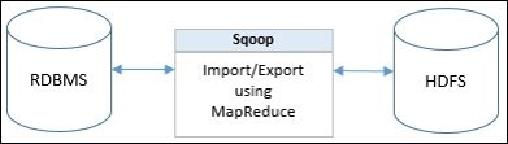
The following diagram shows the two-way flow of data from RDBMS to HDFS and vice
versa:
Once the data is in HDFS, analysts process this data, which generates subsequent output
files. These results, if required, can be exported to an external relational database system
using Sqoop. Sqoop reads delimited files from HDFS, constructs database records, and in-
serts them into the external table.
Sqoop is a highly configurable tool where you can define the columns that need to be im-
ported/exported to and from HDFS. All operations in Sqoop are done using the command-
line interface. Sqoop 2, a newer version of Sqoop, now provides an additional web user in-
terface to perform the importations and exportations.