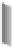Information Technology Reference
In-Depth Information
particular are not options here because NFS datastores use the networking stack, not the stor-
age stack. The VMware NFS client uses two TCP sessions per datastore (as shown in Figure
6.48): one for control trafi c and one for data l ow. The TCP connection for the data l ow is the
vast majority of the bandwidth. With all NIC teaming/link aggregation technologies, Ethernet
link choice is based on TCP connections. This happens either as a one-time operation when the
connection is established with NIC teaming or dynamically, with 802.3ad. Regardless, there's
always only one active link per TCP connection and therefore only one active link for all the
data l ow for a single NFS datastore.
Figure 6.48
Every NFS datas-
tore has two TCP
connections to the
NFS server but only
one for data.
TCP connection for data
NFS export
NFS datastore
TCP connection for control
This highlights that, as with VMFS, the “one big datastore” model is not a good design prin-
ciple. In the case of VMFS, it's not a good model because of the extremely large number of VMs
and the implications on LUN queues (and to a far lesser extent, SCSI locking impact). In the case
of NFS, it is not a good model because the bulk of the bandwidth would be on a single TCP ses-
sion and therefore would use a single Ethernet link (regardless of network interface teaming,
link aggregation, or routing). This has implications for supporting high-bandwidth workloads
on NFS, as we'll explore later in this section.
Another consideration of highly available design with NFS datastores is that NAS device
failover is generally longer than for a native block device. Block storage devices generally can
fail over after a storage processor failure in seconds (or milliseconds). NAS devices, on the other
hand, tend to fail over in tens of seconds and can take longer depending on the NAS device and
the coni guration specii cs. There are NFS servers that fail over faster, but these tend to be rela-
tively rare in vSphere use cases. This long failover period should not be considered intrinsically
negative but rather a coni guration question that determines the i t for NFS datastores, based on
the VM service-level agreement (SLA) expectation.
The key questions are these:
How much time elapses before ESXi does something about a datastore being unreachable?
◆
How much time elapses before the guest OS does something about its virtual disk not
responding?
◆
Failover Is Not Unique to NFS
h e concept of failover exists with Fibre Channel and iSCSI, though, as noted in the text, it is
generally in shorter time intervals. h is time period depends on specifi cs of the HBA confi gura-
tion, but typically it is less than 30 seconds for Fibre Channel/FCoE and less than 60 seconds for
iSCSI. Depending on your multipathing confi guration within vSphere, path failure detection and
switching to a diff erent path might be much faster (nearly instantaneous).