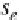Geoscience Reference
In-Depth Information
where
s
e
is the standard error of the mean nearest-neighbor distance, which
is dei ned as
h e null hypothesis
randomness
is tested against two alternative hypotheses,
clustering
and
uniformity or regularity
. h e
Z
statistic has critical values of
1.96 and -1.96 at a signii cance level of 95%. If -1.96<
Z
<+1.96, we cannot
reject the null hypothesis that the data are randomly distributed. If
Z
<-1.96,
we reject the null hypothesis and accept the i rst alternative hypothesis of
clustering. If
Z
>+1.96, we also reject the null hypothesis, but accept the
second alternative hypothesis of uniformity or regularity.
As an example we again use the synthetic data analyzed in the previous
examples.
clear
rng(5)
data = 10 * rand(100,2);
plot(data(:,1),data(:,2),'o')
We i rst compute the pairwise Euclidian distance between all pairs of
observations using the function
pdist
(Section 9.5). h e resulting distance
matrix
distances
is then converted into a symmetric, square format, so that
distmatrix(i,j)
denotes the distance between
i
and
j
objects in the original
data.
distances = pdist(data,'Euclidean');
distmatrix = squareform(distances);
h e following
for
loop i nds the nearest neighbors, stores the nearest-
neighbor distances and computes the mean distance.
for i = 1 : 100
distmatrix(i,i) = NaN;
k = find(distmatrix(i,:) == min(distmatrix(i,:)));
nearest(i) = distmatrix(i,k(1));
end
observednearest = mean(nearest)