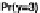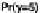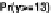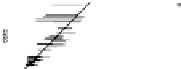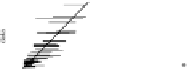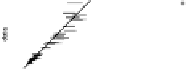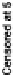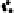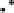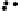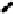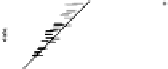Graphics Reference
In-Depth Information
general notation, for some suitable test function T, which may thus be a graph, we
compare T
y
rep
(
y
)
with T
(
)
.
Plots of Data Compared with Replicated Data
Forthe social networks model,wechoosetocompare thedata andthepredictions by
plottingtheobservedversusexpectedproportionsofresponses y
ik
.Foreachsubpop-
ulation k, we compute the proportion of the
respondents for which y
ik
equals
,
,
,
,
,
, and finally those with y
ik
. hese values are then compared to
posterior predictive simulations under the model. Naturally, we plot the uncertainty
intervals of Prob
k
instead of their point estimates.
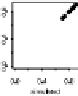
he bottom row of Fig.
.
shows the plots. On the whole, the model fits the
aggregate counts fairly well,but tendstounderpredictthe proportionof respondents
whoknowexactlyonepersoninacategory.Inaddition,thedataandpredictedvalues
for y
y
ik
m
(
=
)
=
andy
=
illustrate that people are more likely to answer with round
numbers.
hethreefirstrowsofFig.
.
showstheplotsforthreealternative models(Zheng
et al.,
). his plot illustrates one of our main principles: whenever we need to
compareaseriesofgraphs,weplotthemsidebysideonthesamepagesothatvi-
sual comparison is e
cient (Bertin,
/
; Tute,
).here is no advantage to
scattering closely related graphs over several pages.
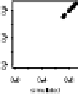
Figure
.
.
Model-checking graphs: observed vs. expected proportions of responses y
ik
of
,
,
,
,
,
, and
. Each row of plots compares actual data to the estimate from one of four fitted
models. he bottom row shows our main model, and the top three rows show the models fitted while
censoring the data at
,
, and
, respectively. In each plot, each dot represents a subpopulation, with
proper name categories in gray, other categories in black, and
% posterior intervals are indicated by
horizontal lines