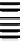Database Reference
In-Depth Information
Job Tracker
HDFS
RPC Reads
Reduce
HDFS
Output
File
Map
Local Writes
Data Splits
Data Node
Data Node
HDFS
Blocks
HDFS
Reduce
Map
HDFS
Output
File
Data Splits
Data Node
RPC Reads
Data Node
HDFS
Map
Local Writes
Data Splits
Data Node
Let's discuss how MapReduce processes the data described in the preceding
diagram. In MapReduce, the irst step is the split process, which is responsible
for dividing the input data into reasonably sized chunks that are then processed
as a single map task. The JobTracker process acts as a manager application and is
responsible for managing the MapReduce applications that run on the cluster. Jobs
are submitted to JobTracker for execution, and it manages them by distributing the
workload. It also keeps a track of all elements of the job, ensuring that failed tasks are
either retried or resubmitted. Multiple MapReduce applications can also be run on a
single Hadoop cluster, and the additional responsibility of JobTracker is to oversee
resource utilization as well.