Cryptography Reference
In-Depth Information
the success probability seems to be independent of the field size
q
;thisisto
be expected, since we are only searching for the (non-)error
positions
,nottheir
values. This is an advantage compared with other algorithms like information
set decoding, where the algorithm complexity grows significantly with
q
(more
than the impact of
q
-ary arithmetic, which applies in our case as well).
Also, note that larger field sizes require larger values
w
when computing the
sets
H
w
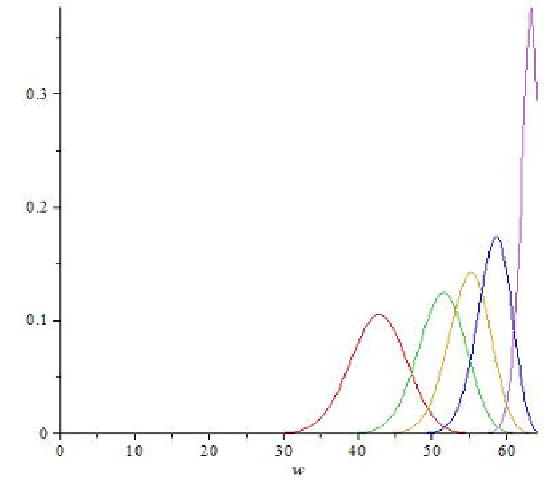
. This is due to the fact that the weight distribution of codes over dif-
ferent fields is not identical. For the above fields
F
q
,the
weight distributions are shown in Figure 1. Those distributions are derived from
Cheung's result that in an (
n,k
)codeover
with
q
∈{
3
,
5
,
7
,
11
,
53
}
F
q
, the ratio of codewords of weight
u
to words of weight
u
is very close to
q
−
(
n
−
k
)
.
(11)
Fig. 1.
Weight distribution of (64
,
40) codes over different fields
F
q
The optimal choice of
b
and
B
is dicult to compute: since vectors
h
of smaller
weight can provide more information about the error positions of
e
, a smaller
set
H
w
is sucient to achieve a given success probability, but it is more dicult
to precompute this set if there exist fewer vectors of this weight in the code. A
good value (or range of values) can be estimated using Equations (10) and (11).
4.1 Comparison with ISD
Information set decoding (ISD) is based on a decoding algorithm by Prange [15].
Improved versions of this attack, e.g. [14] achieve complexities close to theoretical
lower bounds [11,12].