Biomedical Engineering Reference
In-Depth Information
Genomic library
A genomic library is a DNA library containing an organism's genomic
DNA. These are commonly used to facilitate the isolation of a gene with
its flanking sequences. Genomic libraries are used to isolate and help
characterize the intron-exon structure of a gene, and to characterize
regulatory domains, including promoter and enhancer elements.
cDNA library
A cDNA library is a library in which the cloned DNA has been synthe-
sized from mRNA expressed by a particular cell, tissue, or organism. The
ideal cDNA library contains representatives of all expressed mRNAs in
cDNA form at a frequency that is commensurate with the abundance of
the expressed mRNA, but such representative cDNA libraries are diffi-
cult to achieve. cDNA libraries are frequently used to identify and isolate
expressed genes, and to analyze differences in the expression patterns
of genes (both known and unknown) in different cell types, in cells at
different stages of differentiation, or in different tissues. cDNA libraries
can be generated and screened using standard cloning vectors such as
or they can be screened by expression of a protein using vectors
such as
In silico cloning
In silico cloning uses computer-based (“in silico”) search methods to
identify genes. The advantage of in silico cloning is that the need for
some of the benchwork normally required to clone a gene of interest is
bypassed by obtaining as much sequence information as possible from
on-line “libraries”.
The most useful on-line libraries have been those in the Expressed
Sequence Tags (EST) database. The EST database is considered by
many to have represented a turning point in genome research. It was first
proposed in 1991 as a means to enhance the discovery of new genes
and map them in the genome (26). Laboratories from around the world
would sample sequence cDNA clones from a variety of libraries and de-
posit these partial sequences into a central database. This database is
part of GenBank (http://www.ncbi.nlm.nih.gov/dbEST/index.html), which
is part of the National Center for Biotechnology Information supported
by the National Library of Medicine and the National Institutes of Health.
Over the years, the database has accumulated millions of partially over-
lapping and redundant sequences from a variety of organisms. For ex-
ample there are currently over 5.5 million EST sequences from humans,
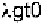
Search WWH ::

Custom Search