Information Technology Reference
In-Depth Information
performance eValuation
cess patterns. The in-disk readahead function is
disabled to highlight the performance impact of
OS readahead.
Not surprisingly the I/O throughput decreases
with more and more random reads. Also notably,
the new readahead algorithm maintains a stable
lead over the legacy one. In the case of 1:100
random:sequential bytes ratio, the throughputs are
17.18MB/s and 22.15MB/s respectively, with the
new readahead showing an edge of 28.9% over the
legacy one. When the ratio goes up to 10:100, the
throughputs decrease to 5.10MB/s and 6.39MB/s,
but still keeps a performance edge of 25.4%.
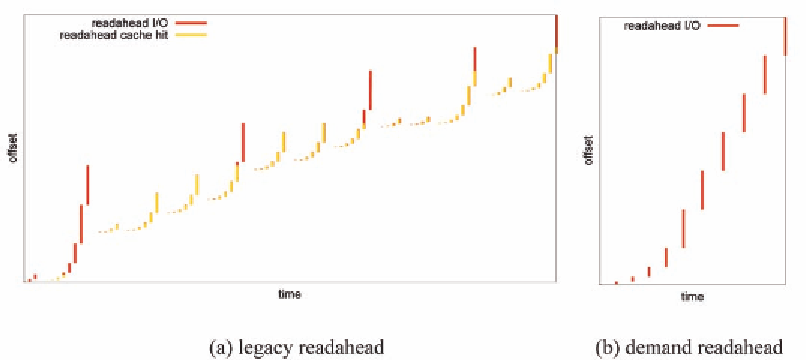
The performance edges originate from the
different readahead behaviors under random
disturbs. Figure 11 demonstrates the readahead
sequences submitted for the first 1600 pages
by the two readahead algorithms. Figure 11(a)
shows vividly how the legacy readahead se-
quences are interrupted by random reads. On
each and every random read, the readahead
window will be shutdown. And then followed
by a new readahead size ramp up process. Due
to the existence of async readahead pages, the
new readahead sequence will be overlapping
with the old one, leading to series of readahead
cache hits. In contrast, the demand readahead
algorithm ramps up and pushes forward the
In this section we explore the readahead perfor-
mances of Linux 2.6.24 and 2.6.22 side by side,
which implements the new and legacy readahead
algorithms respectively. The max readahead size
is set to 1MB for better I/O performance. The
testing platform is a single Hitachi
(R)
Deskstar
(TM)
T7K250 160GB 7200RPM 8MB hard disk and
Intel
(R)
Core
(TM)
2 E6800 2.93GHz CPU. The
selected comparison experiments illustrate how
much impact readahead algorithms can have on
single disk I/O performance. One can expect much
larger differences for disk arrays.
intermixed random and
Sequential reads
We created a 200MB file to carry out the intermixed
4KB random and sequential reads. The sequential
stream begins at start of file and stops at middle
of file, while the random reads land randomly in
the second half of the file. We created ten access
patterns where the amount of sequential reads
are fixed at 100MB and the amount of random
reads increase from 1MB to 10MB. Figure 10(a)
describes the first access pattern. Figure 10(b)
shows the I/O throughputs for each of the 10 ac-
Figure 11. Comparison of readahead sequences under random disturbs
Search WWH ::

Custom Search