Information Technology Reference
In-Depth Information
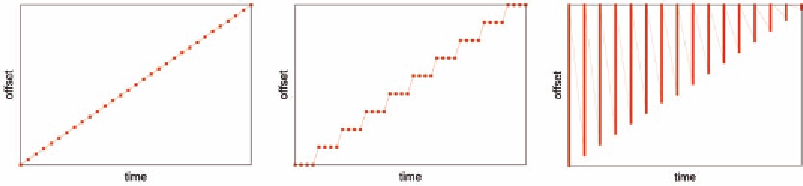
Figure 8. The trivial, unaligned, and retried sequential reads
However, once the thrashings stop, the reada-
head algorithm immediately reverts back to the
normal behavior of ramping up the window size
by 2 or 4, leading to a new round of thrashings.
On average, about half of the readahead pages
will be lost and re-read from disk.
Besides the wastage of memory and bandwidth
resources, there are much more destructive disk
seeks. When thrashing is detected, the legacy
readahead takes no action to recover the lost
pages inside the readahead windows. The VFS
read routine then has to fault them in one by one,
generating a lot of tiny 4KB I/Os and hence disk
seeks. Overall, up to half pages will be faulted in
this destructive way.
Our proposed framework has basic safeguards
against readahead thrashing. Firstly, the first read
after thrashing makes a cache miss, which will
automatically restart readahead from the current
position. Therefore it avoids the catastrophic
1-page tiny I/Os suffered by the legacy readahead.
Secondly, the size ramp up process may be starting
from a small initial value and keep growing expo-
nentially until thrashing again, which effectively
keeps the average readahead size above half of the
thrashing threshold. If necessary, more fine grained
control can be practiced after thrashing.
cases, the consecutive test offset == prev_offset
+ 1 can fail even when an application is visiting
data consecutively.
Unaligned Reads.
File reads work on byte
ranges, while readahead algorithm works on
pages. When a read request does not start or stop
at page boundaries, it becomes an “unaligned
read”. Sequential unaligned reads can access the
same page more than once. For example, 1KB
sized unaligned reads will present the readahead
algorithm with a page series of {0, 0, 0, 0, 1, 1,
1, 1, …} To cover such cases, this sequentiality
criterion has been added: offset == prev_offset.
Retried Reads.
In many cases --- such as non-
blocking I/O, the retry based Linux AIO, or an
interrupted system call --- the kernel may interrupt
a read that has only transferred partial amounts
of data. A typical application will issue “retried
read” requests for the remaining data. The possible
requested page ranges could be: {[0, 1000], [4,
1000], [8, 1000], …}. Such pattern confuses the
legacy readahead totally. They will be taken as
oversize reads and trigger the following readahead
requests: {(0, 64), (4, 64), (8, 64), …}. Which
are overlapped with each other, leading to a lot
of readahead cache hits and tiny 4-page I/Os.
The new call convention can mask off the retried
parts perfectly, in which readahead is triggered by
the real accessed pages instead of spurious read
requests. So the readahead heuristics won't even
be aware of the existence of retried reads.
non-trivial Sequential reads
Interestingly, sequential reads may not look like
sequential. Figure 8 shows three different forms of
sequential reads that have been discovered in the
Linux readahead practices. For the following two
Search WWH ::

Custom Search