Information Technology Reference
In-Depth Information
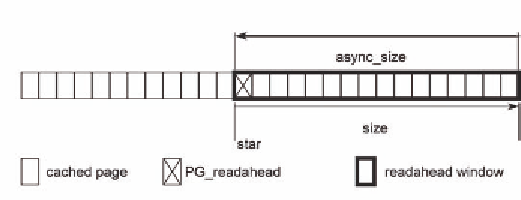
Figure 5. For a typical readahead window, async_size equals to size, and PG_readahead lies in the
first page
be a great challenge to the readahead algorithm.
The interleaving of several sequential streams
may be perceived as random reads.
In theory, it is possible to track the state of
each and every stream. However the cost would
be unacceptable: since each read request may start
a new stream, we will end up remembering every
read in the case of random reads. ZFS takes this
approach but limits the number of streams it can
track to a small value. The implementation also
has to deal with the complexity to dynamically al-
locate, lookup, age and free the stream objects.
Linux takes a simple and stupid approach: to
statically allocate one readahead data structure
for each file descriptor. This is handy in serving
the common case of one stream per file descrip-
tor, however it leaves the support for multiple
interleaved streams an open question.
When there are multiple streams per file de-
scriptor, the streams will contend the single space
slot for read offset and readahead window, and
end up overwriting each other's state. This gives
rise to two problems. Firstly, given an unreliable
prev_offset, how do we know the current read
request is a sequential one and therefore should
be prefetched? Secondly, given an unreliable
readahead window, how do we know it is valid for
the current stream and if not, how can we recover
it? The first problem has in fact been addressed in
the previous subsection. It is also straightforward
to validate the ownership of a readahead window:
if it contains the current PG_readahead page, then
it is the readhead window for the current stream.
Otherwise we have to seek alternative ways for
finding out the lost information about readahead
window.
Fortunately, we found that the lost readahead
window information can be inferred from the page
cache. Figure 5 shows the typical status of a page
cache. The application hits the PG_readahead
page and is triggering an interleaved readahead.
To recover the readahead window information,
we scan forward in the page cache from the cur-
rent page to the first missing page. The number
of pages in between is exactly async_size. As we
know that async_size equals to size for all subse-
quent readaheads and at least size/2 for the initial
readahead, we can safely take async_size as size,
and calculate the next readahead size from it.
readahead Sequence
Assume the sequence of readahead for a sequen-
tial read stream to be A0, A1, A2, … We call
A0 the “initial readahead” and A1, A2, … the
“subsequent readaheads”. The initial readahead is
typically synchronous in that it contains the cur-
rently requested page and the reader have to stop
and wait for the readahead I/O. The subsequent
readaheads can normally be asynchronous in that
the readahead pages are not immediately needed
by the application.
A typical readahead sequence starts with a
small initial readahead size, which is inferred
Search WWH ::

Custom Search