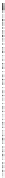Graphics Reference
In-Depth Information
L
varies as a function of
v
i
. But in the absence of other information, the
product
Lf
r
is likely to be larger when
f
r
is large and smaller when
f
r
is small. We can
therefore hope to reduce variance in our estimate by choosing samples in a way
that's proportional to
f
r
, or better still, proportional to
n
(
P
)
,
which we call the
cosine weighted BRDF.
This may not be possible, but it may be
possible to choose them in a way that's at least
related
to
f
r
or the cosine weighted
BRDF. This can help reduce variance substantially. In fact, it's easy to see where
this kind of importance sampling will help most.
v
i
→
f
r
(
P
,
v
o
)
v
i
·
v
i
,
• If the surface is mostly lit by a few point lights, then the variation in
L
will
usually dominate the variation in
f
r
in determining where the integrand is
large or small.
• If the surface is mostly lit by diffusely reflected light coming from all dif-
ferent places, but is itself highly specular, then the shape of
f
r
dominates
in determining the size of the integrand, and importance sampling with
respect to the cosine weighted BRDF is likely to reduce variance a lot.
Unfortunately, when we build a rendering system, we don't necessarily know
what kind of scenes we'll be rendering. It would be nice to be able to combine
the two strategies (use the cosine weighted BRDF as the importance function, or
use some approximation of the arriving light field as the importance function) in a
way that varies according to the particular situation. A technique called
multiple
importance sampling
(see Section 31.18.4) allows us to do just that.
We've discussed discrete and continuum probabilities, but there's a third kind,
which we'll call
mixed probabilities,
that comes up in rendering. They arise
exactly from the impulses in bidirectional scattering distribution functions
(BSDFs), or the impulses caused by point lights. These are probabilities that are
defined on a continuum, like the interval
[
0, 1
]
, but are not defined strictly by a
density. Consider the following program, for example:
1
2
3
4
if uniform(0, 1) > 0.6 :
return 0.3
else :
return uniform(0, 1)
0.7
Sixty percent of the time this program returns the value 0.3; the other 40% of the
time it returns a value uniformly distributed on
[
0, 1
]
. The return value is a random
variable that has a
probability mass
of 0.6 at 0.3, and a pdf given by
d
(
x
)=
0.4
at all other points. We'd
like
to be able to say that the pdf is given by
d
(
x
)=
0.4
0.6
0.5
0.4
0.3
0.2
x
=
0.3
0.1
x
=
0.3
,
(30.70)
0.6
·∞
0.0
0.0
0.2
0.4
0.6
0.8
1.0
as shown schematically in Figure 30.10, but this makes no sense, literally. In the
language of Chapter 18, we could instead say that the pdf was the sum of the
constant function 0.4 and the delta function 0.6
Figure 30.10: A mixed probabil-
ity. The red stem (vertical line)
indicates a probability mass. The
blue graph (horizontal line) indi-
cates a density.
0.3
)
. Or we can just say
that it's a random variable that has a probability mass at the point 0.3. In any
case, a
random variable with mixed probability
is one for which there is a finite
· δ
(
x
−