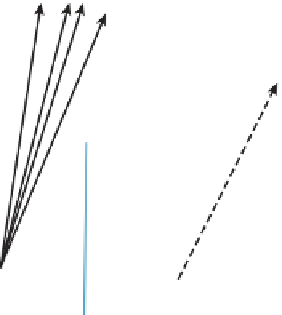Graphics Reference
In-Depth Information
work to distribute over multiple execution units. Deeper in the tree there is plenty
of work, but because the lengths of paths may vary, the work of load balancing
across multiple units may dominate the actual search itself. Furthermore, if the
computational units share a single global memory, then the bandwidth constraints
of that memory may still limit net performance. In that case, adding more compu-
tational units can
reduce
net performance because they will overwhelm the mem-
ory and reduce the coherence of memory access, eliminating any global cache
efficiency.
There are opportunities for scaling nearly linearly in the number of compu-
tational units when performing
multiple
visibility queries simultaneously, if they
have sufficient main memory bandwidth or independent on-processor caches. In
this case, all threads can search the tree in parallel. Historically the architectures
capable of massively parallel search have required some level of programmer
instruction batching, called
vectorization.
Also called Single Instruction Multi-
ple Data (SIMD), vector instructions mean that groups of logical threads must
all branch the same way to achieve peak computational efficiency. When they do
branch the same way, they are said to be branch-coherent; when they do not, they
are said to be divergent. In practice, branch coherence is also a de facto require-
ment for any memory-limited search on a parallel architecture, since otherwise,
executing more threads will require more bandwidth because they will fetch dif-
ferent values from memory.
There are many strategies for BSP search on SIMD architectures. Two that
have been successful in both research and industry practice are
ray packet trac-
ing
[WSBW01, WBS07, ORM08] and
megakernel tracing
[PBD
+
10]. Each
essentially constrains a group of threads to descend the same way through the tree,
even if some of the threads are forced to ignore the result because they should
have branched the other way (see Figure 36.10). There are some architecture-
specific subtleties about how far to iterate before recompacting threads based on
their coherence, and how to schedule and cache memory results.
Figure 36.10: Packets of rays with similar direction and origin may perform similar traver-
sals of a BSP tree. Processing them simultaneously on a parallel architecture can amortize
the memory cost of fetching nodes and leverage vector registers and instructions. Rays that
diverge from the common traversal (illustrated by dashed lines) reduce the efficiency of this
approach.