Database Reference
In-Depth Information
to ZooKeeper but the connection closes immediately. This could be a sign that
the server has too many connections (30 is the default). Consider inspecting
your ZK server logs for that error and then make sure you are reusing
HBaseConfiguration as often as you can. See HTable's javadoc for more
information.
Make sure that your /etc/hosts file entries are defined correctly and that ZooKeeper is working correctly before
you move on to start HBase.
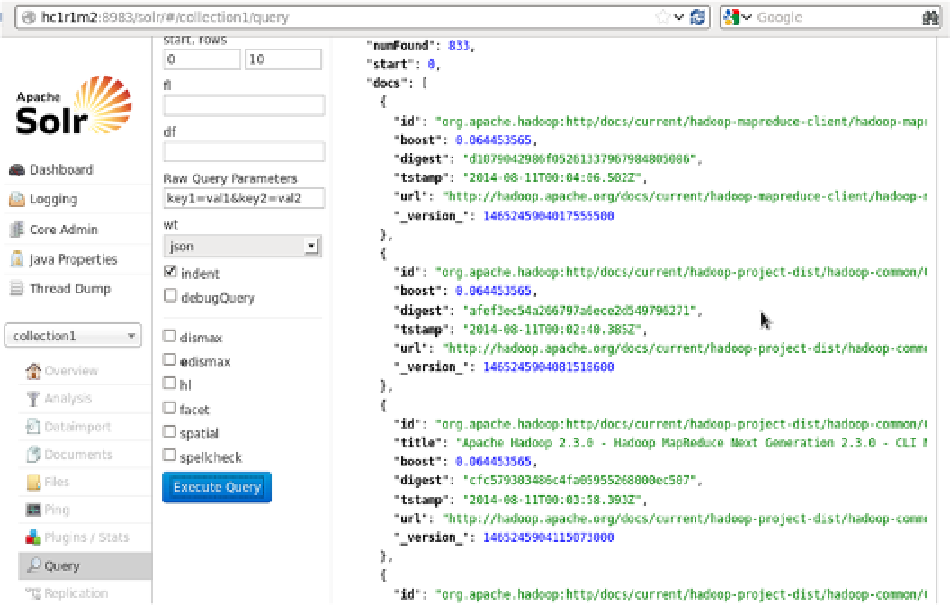
As for architecture example 1, you can check the Solr query page for your results. For this example, because the
seed URL was from my own site, the query found the apache URLs, as shown in Figure
3-4
.
Figure 3-4.
Solr output showing the crawl data
A Brief Comparison
Of the two architecture examples given in this chapter, the second, using HBase, was the most difficult to use. This
may be the future direction that Nutch is taking, but there are a lot more configuration items to take care of. There
are more components to worry about and check, plus more potential areas of failure. Having said that, the second
architecture example gives you the ability to explicitly choose the storage architecture. If for some reason at a future
date you need to use an alternative system to HBase that Gora supports, you will be able to do that.
You have only used Hadoop V1 in both of these examples. If time had allowed, it would have been useful to use
Hadoop V2 as well. In that case, you would have needed to rebuild both HBase and Nutch using Hadoop V2 libraries.
Nevertheless, it would have been interesting to compare the Nutch processing time using Hadoop V1 and V2.
Search WWH ::

Custom Search