Database Reference
In-Depth Information
The segments directory has a list of the segments that have been processed:
[hadoop@hc1nn nutch]$ hadoop fs -ls /user/hadoop/crawl/segments
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2014-04-06 14:08
/user/hadoop/crawl/segments/20140406140827
drwxr-xr-x - hadoop supergroup 0 2014-04-06 14:17
/user/hadoop/crawl/segments/20140406141732
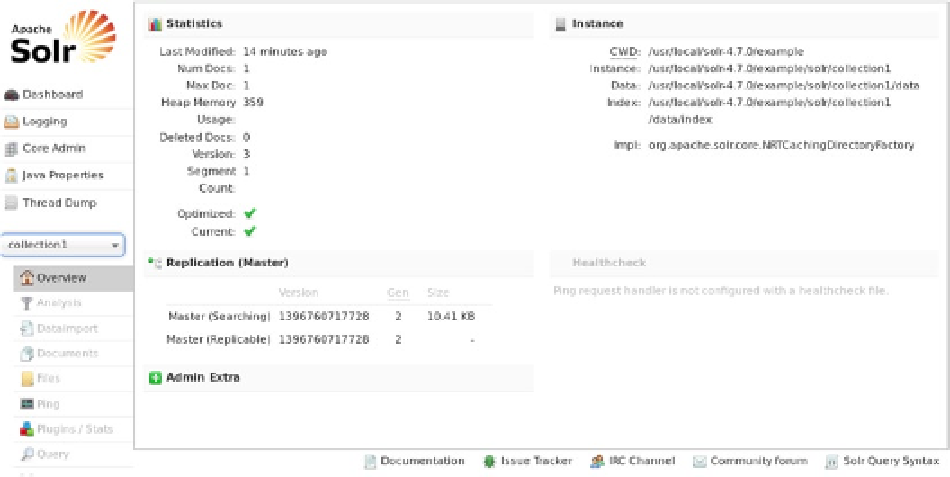
You now have data in Solr. To see it, go to the Solr admin web page at
http://localhost:8983/solr/
and select
“collection1” in the core selector drop-down menu (halfway down the left side). Figure
3-2
shows that the sample data
has loaded into Solr. Specifically, under the Replication heading on the right, you can see that around 10 KB of data
loaded from the short crawl of the Semtech Solutions web page. Although this is a comparatively small sum of data for
a large-scale distributed system, it serves to prove that the crawl executed and indexed correctly.
Figure 3-2.
The Solr sample data after processing
To examine some of the actual data in Solr, you select the Query option (bottom left). An Execute Query option
will appear; select it to see the crawl results. Figure
3-3
shows a sample of the data that Solr has indexed from the
website at the single URL specified in the seed file.
Search WWH ::

Custom Search