Database Reference
In-Depth Information
You can also check the log file under $SOLR_HOME/example/logs/. If there are no errors, then try connecting to
the Solr admin client at:
http://localhost:8983/solr/admin/
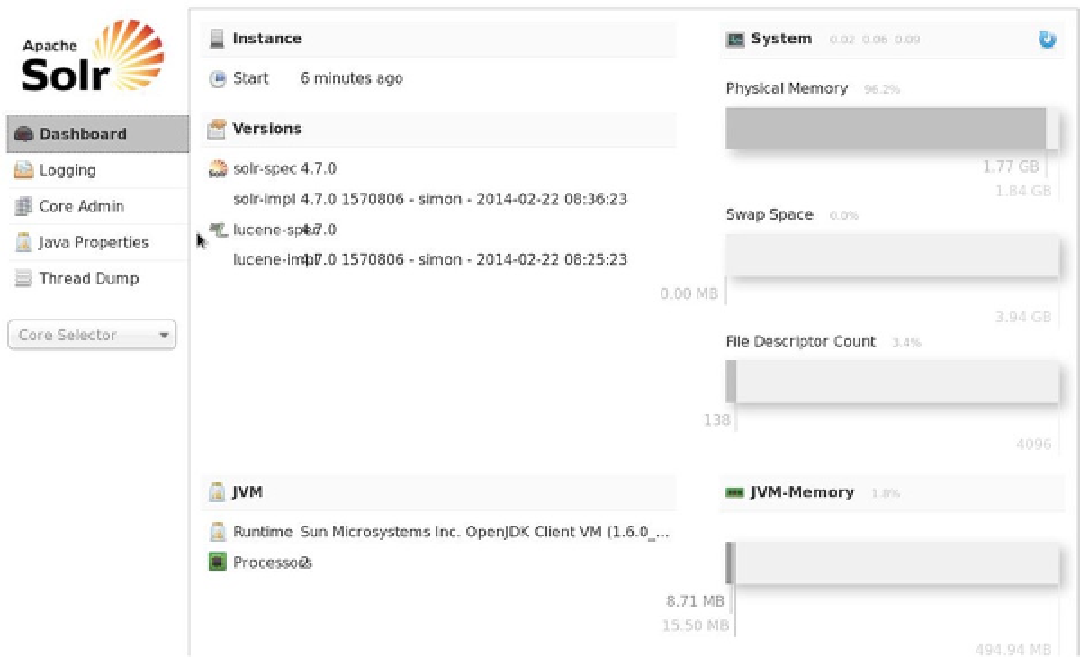
The Solr admin client (Figure
3-1
) contains logging and administrative functions, as well as the core selector that
you will use shortly to examine the results of Solr indexing.
Figure 3-1.
The Solr administration user interface
Now that you have Solr running without error and you can connect to its admin client, you are ready to run Nutch
and do a simple web crawl using Hadoop as the storage mechanism.
Running Nutch with Hadoop 1.8
You are ready to run the first crawl using Nutch and Hadoop. For doing this, I have created a seed file on the Linux file
system containing the initial website to crawl. I have also added a single URL to the file, my own website.
1
[hadoop@hc1nn nutch]$ ls -l urls
total 4
-rw-rw-r--. 1 hadoop hadoop 19 Apr 5 13:14 seed.txt
1
I own the site and it's contents, so there are no issues with processing the site contents and displaying them here.
Search WWH ::

Custom Search