Database Reference
In-Depth Information
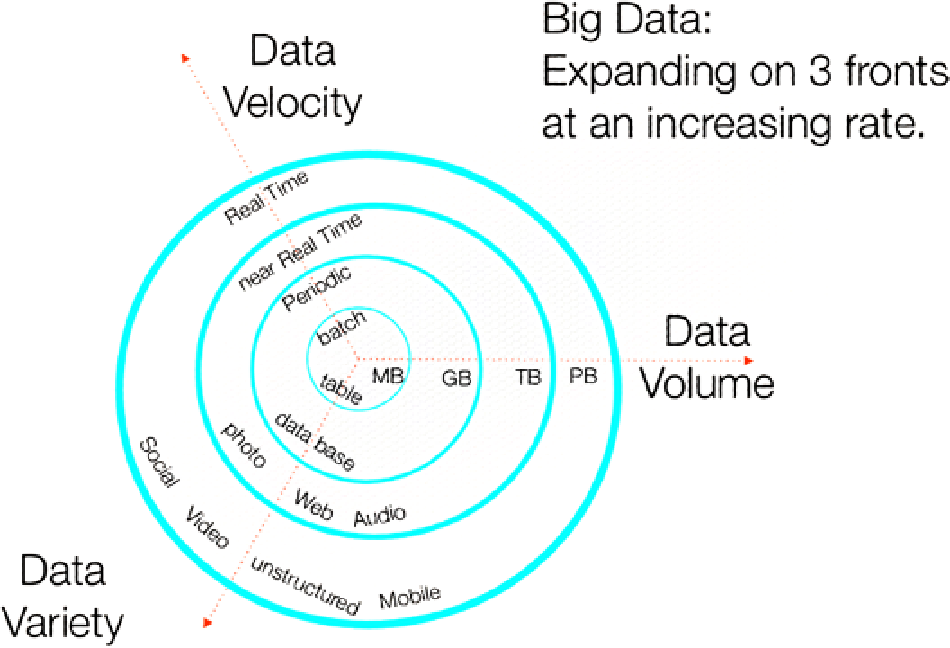
Figure 1-1.
Diya Soubra's multidimensional 3V diagram showing big data's expansion over time
You can find real-world examples of current big data projects in a range of industries. In science, for example,
a single genome file might contain 100 GB of data; the “1000 Genomes Project” has amassed 200 TB worth of
information already. Or, consider the data output of the Large Hadron Collider, which produces 15 PB of detector data
per year. Finally, eBay stores 40 PB of semistructured and relational data on its Singularity system.
The Potentials and Difficulties of Big Data
Big data needs to be considered in terms of how the data will be manipulated. The size of the data set will impact
data capture, movement, storage, processing, presentation, analytics, reporting, and latency. Traditional tools quickly
can become overwhelmed by the large volume of big data. Latency—the time it takes to access the data—is as an
important a consideration as volume. Suppose you might need to run an ad hoc query against the large data set or a
predefined report. A large data storage system is not a data warehouse, however, and it may not respond to queries in
a few seconds. It is, rather, the organization-wide repository that stores all of its data and is the system that
feeds into
the data warehouses for management reporting.
One solution to the problems presented by very large data sets might be to discard parts of the data so as to
reduce data volume, but this isn't always practical. Regulations might require that data be stored for a number of
years, or competitive pressure could force you to save everything. Also, who knows what future benefits might be
gleaned from historic business data? If parts of the data are discarded, then the detail is lost and so too is any potential
future competitive advantage.
Instead, a parallel processing approach can do the trick—think divide and conquer. In this ideal solution, the
data is divided into smaller sets and is processed in a parallel fashion. What would you need to implement such
an environment? For a start, you need a robust storage platform that's able to scale to a very large degree (and
Search WWH ::

Custom Search