Database Reference
In-Depth Information
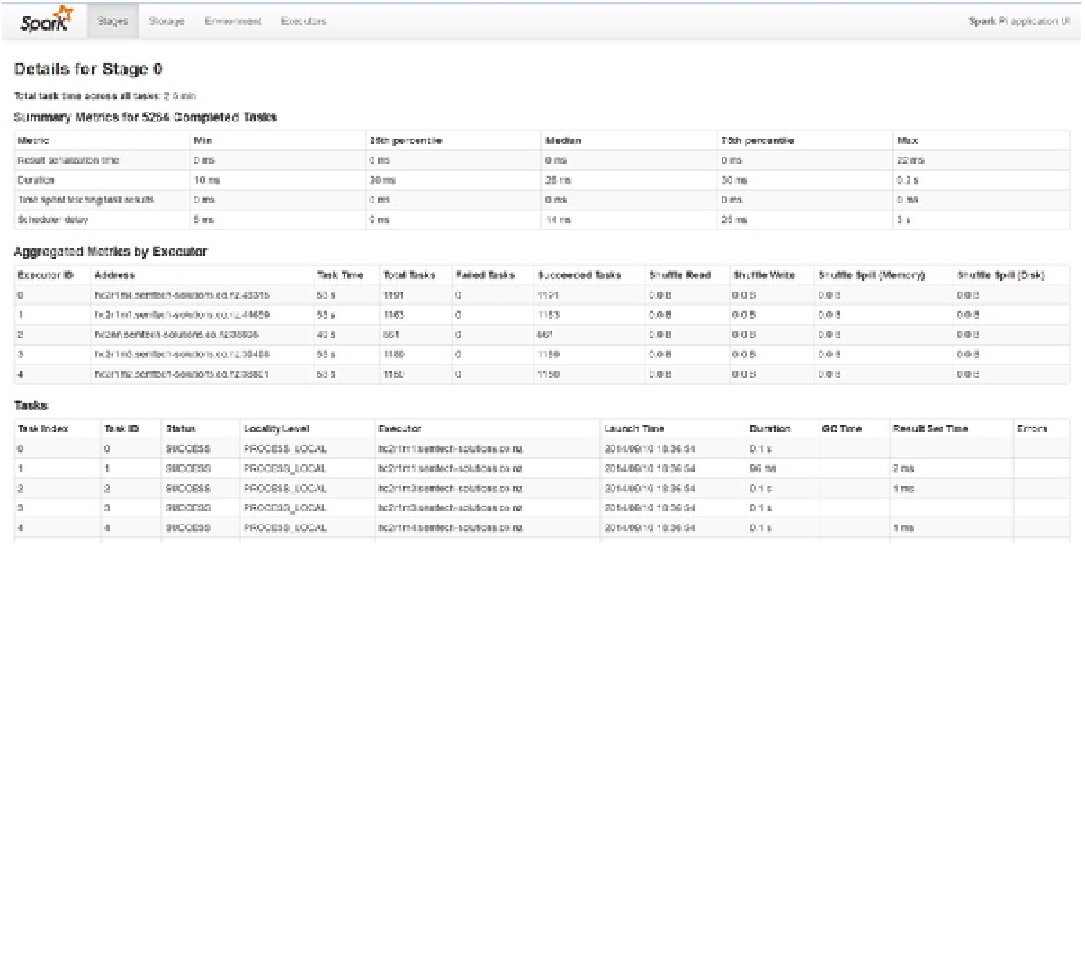
By clicking the Executors tab at the top of the Spark Application interface, I can examine details of the application
task, as shown in Figure
9-8
. I can see the spread of tasks across the cluster nodes and the task times by node, as well
as a list of tasks, the nodes they run on, their execution times, and their statuses. The Summary Metrics section also
contains minimum, maximum, and percentile information for details like serialization, duration, and delay.
Figure 9-8.
Spark Application interface shows job executors
As you can see from these simple examples, the Spark cluster is easy to install, set up, and use. To investigate
Spark in greater detail, visit the Apache Software Foundation website for Apache Spark at
spark.apache.org
.
Spark SQL
Rather than using the default Spark context object
sc
, you can create an SQL context from the default Spark context
and process CSV data using SQL. Spark SQL is an incubator project, however; it is not a mature offering at this
time. For instance, its APIs may yet change, and the version in CDH5 no longer reflects Spark SQL's latest functions.
Despite that, it does offer some interesting features for memory-based SQL cluster processing. I use a simple example
of CSV file processing using Spark SQL, based on a schema-based RDD example at
https://spark.apache.org/
■
Note
For the latest details on spark sQl, see the spark website at
spark.apache.org
.
Search WWH ::

Custom Search