Database Reference
In-Depth Information
The result is 12 lines; checking that total by using the Linux
grep
command piped to the same
wc
command gives
the same result:
[root@hc2nn fuel_consumption]# grep ACURA scala.csv | wc -l
12
Interactively typing the shell commands is useful for short, simple tasks. For larger scripts, you can use the
spark-submit
command to submit applications to the Spark cluster. For instance, I use one of the examples in the
spark-examples application library available under /usr/lib/spark/examples/lib/ in the CDH5 release (which is
supplied with the Spark install):
[root@hc2nn ~]# cd /usr/lib/spark/examples/lib/
[root@hc2nn lib]# ls -l spark-examples_2.10-1.0.0-cdh5.1.2.jar
-rw-r--r-- 1 root root 734539 Aug 26 15:07 spark-examples_2.10-1.0.0-cdh5.1.2.jar
I can execute example applications from this library on the cluster and monitor them using the master user
interface. For instance, the following code uses the
spark-submit
command to run the SparkPi example program
from the examples library. It sets the memory to be used on each worker at 700 MB and the total cores to be used at
10. It uses the same master Spark URL to connect to the cluster and specifies 10,000 tasks/iterations:
[root@hc2nn ~]# spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hc2nn.semtech-solutions.co.nz:7077 \
--executor-memory 700M \
--total-executor-cores 10 \
/usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.2.jar \
10000
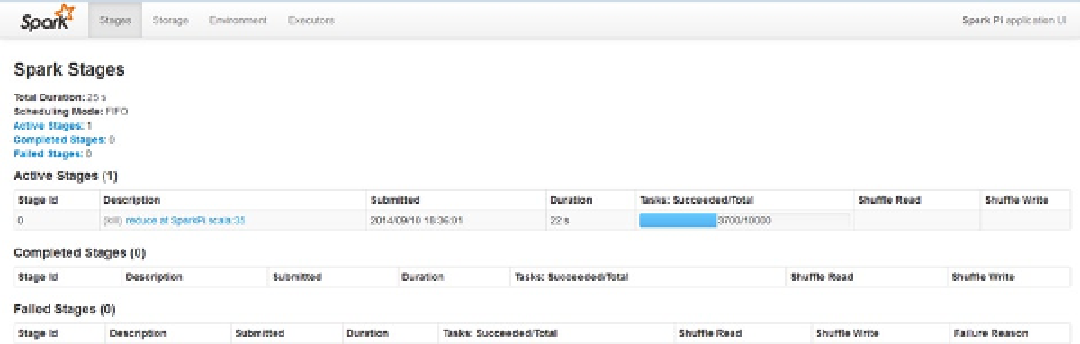
Checking the Spark Application interface for this application in Figure
9-7
shows the application details and the
progress of the job, such as the duration of the application run. I can also see that the default scheduling mode of FIFO
(first in, first out) is being used. As with YARN, I can set up a fair scheduler for Spark. In the Active Stages section, the
blue bar shows the progress of the application run.
Figure 9-7.
Spark Application interface shows details of the job
Search WWH ::

Custom Search