Database Reference
In-Depth Information
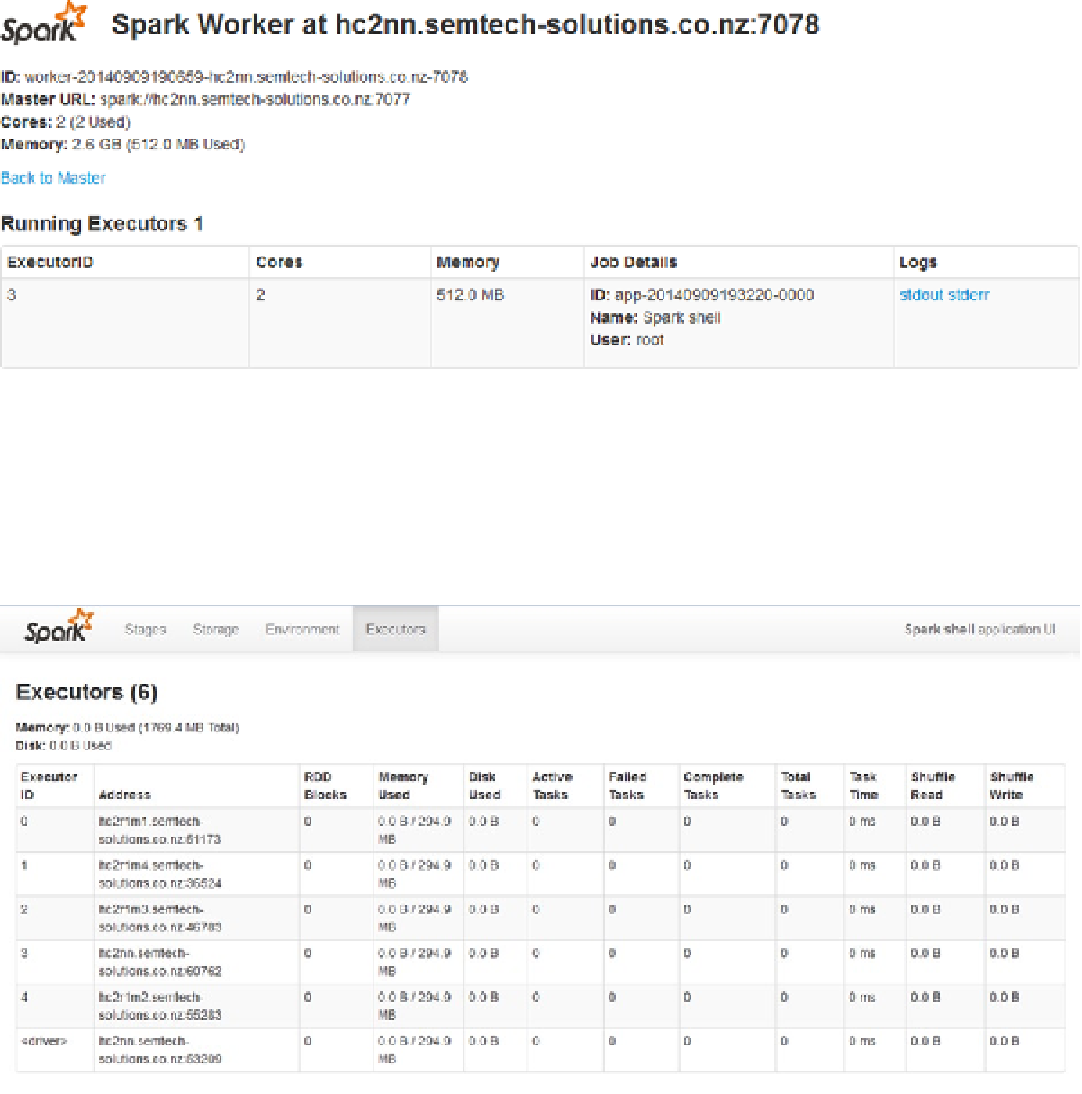
Figure 9-5.
Spark Worker user interface
The work of a given application is spread across the cluster over a series of worker executors on each node. To
reach the application user interface, I simply click an application listed on the Spark Master interface that is in the
Running Applications section, as shown in Figure
9-4
. The list of executors for this application is is then shown in
Figure
9-6
.
Figure 9-6.
Spark application interface
Executors are the tasks based on the cluster worker nodes that process and store an application's data on the
Spark cluster. Figure
9-6
shows that each executor has a unique ID and address. It also shows the state of the executor
in terms of memory and disk, plus the task time.
So, when the interactive Spark shell is running, what can you do with it? To demonstrate a simple script, I read a
Linux-based CSV file from HDFS, run a line count on it in memory, and then do a string search on it. I also confirm the
results by checking the output against Linux commands.
Search WWH ::

Custom Search