Database Reference
In-Depth Information
My SQL-based example shows that Spark-based information can be accessed using SQL. Although Spark
processing is not included in Chapter 10's discussion of Talend and Pentaho, both tools integrate with Spark to offer
visual object-based data manipulation.
The first step in running a Spark script interactively in the Spark shell is to set the master URL displayed on the
Spark Master user interface to be the Spark URL:
[root@hc2nn ~]# spark-shell --master spark://hc2nn.semtech-solutions.co.nz:7077
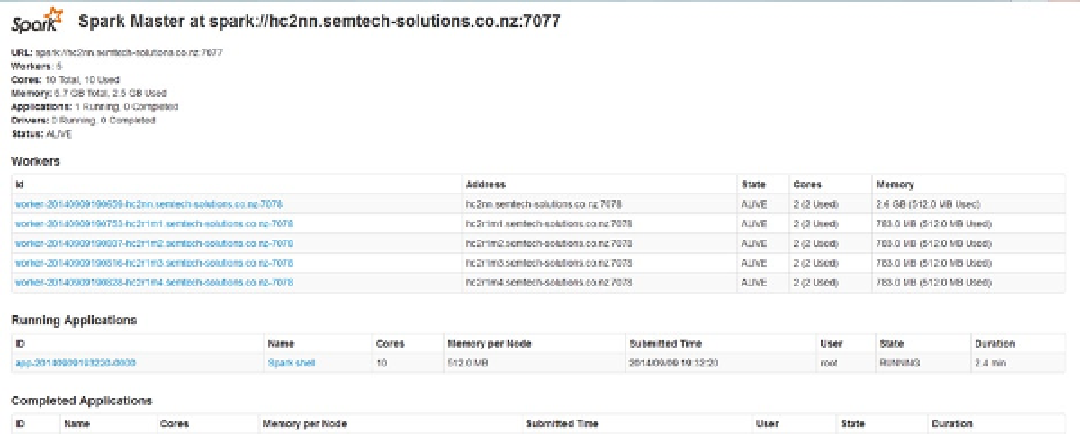
As shown in Figure
9-4
, the Spark shell application is now visible on the Spark Master user interface. The Running
Applications section in Figure
9-4
lists the appplication's ID and name, as well as the number of cores and the memory
available to the application. I can also check the application's submission time, state, user, and duration of its run.
Figure 9-4.
Spark Master interface with applications listed
If I click one of the worker node IDs listed in the Workers section of the Spark Master interface, I can drill down
for more information, as shown in Figure
9-5
. This detailed view shows the cores and memory available on the worker
node plus the executor for the running Spark shell on that node. I click the Back to Master link to return to the Spark
Master interface.
Search WWH ::

Custom Search