Database Reference
In-Depth Information
Figure 6-4.
A Storm tuple
Figure 6-5.
A Storm stream
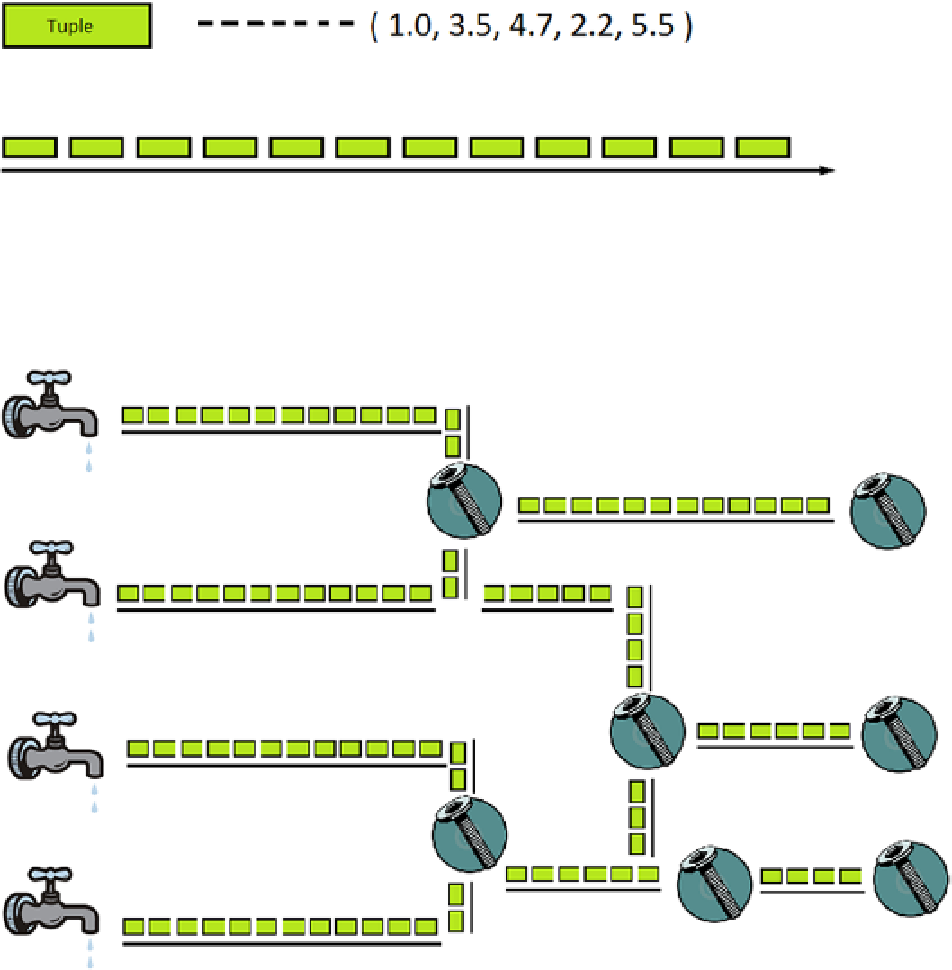
Data sources in Storm are call spouts, while the joints between the streams are called bolts. The input to a stream
might be a spout or a bolt. Bolts can connect stream outputs to inputs from or to other streams. Figure
6-6
shows a
simple Storm topology. Multiple spouts and bolts have been used to merge stream data.
Figure 6-6.
An simple Storm topology
Storm has a master process called a Nimbus and slave processes called supervisors. Configuration is managed
via ZooKeeper servers. The Nimbus master handles the monitoring and distribution of code and tasks to the slaves.
Hadoop runs potentially long-running batch jobs that will eventually end. Storm provides real-time trend processing
of endless stream-based data that will run until it is manually stopped.
As an incubator project, Storm has not yet matured to the level of a full Apache project. It demands a little more
work than is required of more mature systems to source and build the components. Storm depends on ZeroMQ
(a messaging system) and JZMQ (Java Bindings for ZeroMQ), so you need to install these before you install Storm
itself. In the next sections, I show how to install ZeroMQ, JXMQ, and Storm. Remember, though, that each of the
following installations should be carried out on each server on which Storm will run. You will also need ZooKeeper,
the installation for which was described in Chapter 2. Once you check that everything is operating without error,
you'll be able to follow my demonstration of the Storm interface and an example of the code samples that Storm
provides on the Storm cluster that I build.
Search WWH ::

Custom Search