Database Reference
In-Depth Information
You can see that the rawdata table was created, but how much data does it contain? To check the row count of
the Hive rawdata table, you use the following:
hive> select count(*) from rawdata;
Total MapReduce jobs = 1
Launching Job 1 out of 1
......
Total MapReduce CPU Time Spent: 2 seconds 700 msec
OK
20031
Time taken: 25.098 seconds
Success is confirmed: the table in Hive contains 20,031 rows, which matches the MySQL table row count.
As you can see from this brief introduction, Sqoop is a powerful relational database data import/export tool for
Hadoop. You can even use Sqoop in an Oozie workflow and schedule complex ETL flows using Sqoop, Pig, and Hive
scripts. Also, you can carry out incremental loads with such Hive options as
--incremental
and
--check-column
.
This would be useful if you were receiving periodic data-feed updates from a relational database. Check the
sqoop.
apache.org
website to learn more.
So with Sqoop, you have seen an example of moving data between a relational database and Hadoop. But what if
the data that you wish to move is in another type of data source? Well, that is where the Apache Flume tool comes into
play. The next section describes it and provides an example of its use.
Moving Data with Flume
Apache Flume (
flume.apache.org
) is an Apache Software Foundation system for moving large volumes of log-based
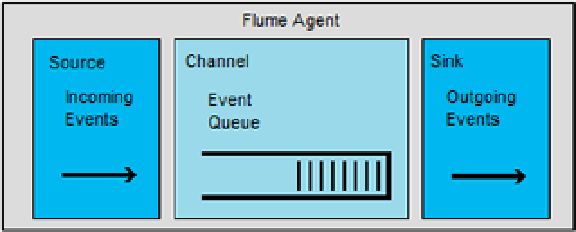
data. The Flume data model is defined in terms of agents, where an agent has an event source, a channel, and an event
sink. Agents are defined in Flume configuration files. The source describes the data source. The channel receives event
data from the source and stores it. The sink takes event data from the channel. Figure
6-1
provides a simple example of
a Flume agent; it is the building block of the Flume architecture.
Figure 6-1.
The Flume agent
The sink might pass data to the source of another agent or write the data to a store like HDFS, as I'll demonstrate
in the sections that follow. You can build complex topologies to process log or event data, with multiple agents passing
data to a single agent or to agents processing data in parallel. The following two examples show simple architectures
for Flume. Figure
6-2
shows a hierarchical arrangement, with Flume agents on the left of the diagram passing data on
to subagents that act as collectors for the data and then store the data to HDFS.
Search WWH ::

Custom Search