Database Reference
In-Depth Information
•
It offers resilience via data replication.
•
It offers automatic failover in the event of a crash.
•
It automatically fragments storage over the cluster.
•
It brings processing to the data.
•
Its supports large volumes of files—into the millions.
The third point comes with a caveat: Hadoop V1 has problems with very large scaling. At the time of writing, it is
limited to a cluster size of around 4,000 nodes and 40,000 concurrent tasks. Hadoop V2 was developed in part to offer
better resource usage and much higher scaling.
Using Hadoop V2 as an example, you see that there are four main component parts to Hadoop.
Hadoop Common
is a set of utilities that support Hadoop as a whole.
Hadoop
Map Reduce
is the parallel processing system used by
Hadoop. It involves the steps Map, Shuffle, and Reduce. A big volume of data (the text of this topic, for example) is
mapped
into smaller elements (the individual words), then an operation (say, a word count) is carried out locally
on the small elements of data. These results are then
shuffled i
nto a whole, and
reduced
to a single list of words and
their counts.
Hadoop
YARN
handles scheduling and resource management. Finally,
Hadoop Distributed File System
(HDFS)
is the distributed file system that works on a master/slave principle whereby a name node manages a cluster
of slave data nodes.
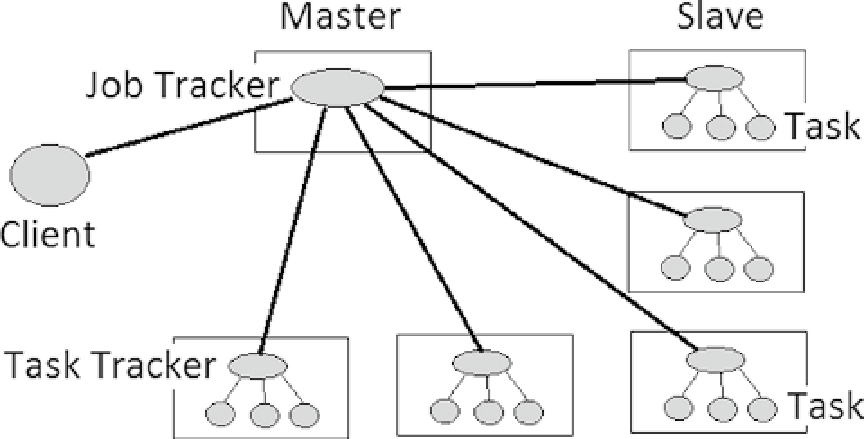
The Hadoop V1 Architecture
In the V1 architecture, a master Job Tracker is used to manage Task Trackers on slave nodes (Figure
2-1
). Hadoop's
data node and Task Trackers co-exist on the same slave nodes.
Figure 2-1.
Hadoop V1 architecture
Search WWH ::

Custom Search