Information Technology Reference
In-Depth Information
In order to provide a statistical validation for the effectiveness of our proposed
model, the datasets are divided into two parts for training and testing: the first
n
pe-
riods of the data is used to train the model and the remaining data is used to for vali-
dation. For instance, the data of 1992 through 1996 can be used for training, and the
data for the remaining years (1997-2012) can be used to test the models learned in the
training stage.
Table 1 show an illustration of the CV's used for this study. For example, for the
yearly data, CV=5 means the data of the first 5 years (years 199206 through 199406)
is used for training and the other years are used for testing.
Table 1.
Periods of CV
CV 199206 199212 199306 199312 199406 ...... 201206 201212
4
training
testing
5
training
testing
...
training
testing
41
training
testing
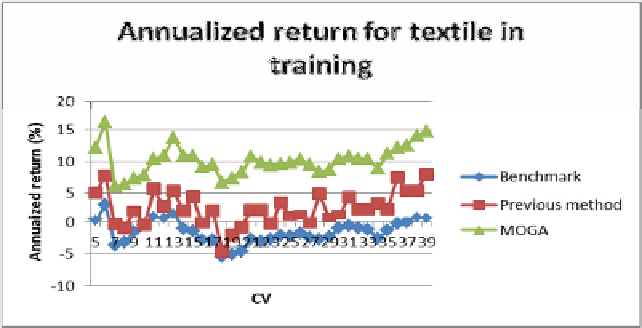
We compare the performance discrepancy of the benchmark, our previous method
[2], and our current MOGA method. Here the benchmark means the annualized return
from selecting all the stocks in the sector. Figures 3 and 4 provide the comparison of
annualized returns for the textile industry for the training and the testing phases, re-
spectively. As can be seen, the proposed model acquired in the training phase signifi-
cantly outperforms both the benchmark and our previous method in all of the CV's.
Furthermore, these trained models by our method are also able to outperform the oth-
er two methods in all of the CV's in the testing phase.
Fig. 3.
Annualized return for textile in training












Search WWH ::

Custom Search