Information Technology Reference
In-Depth Information
to perform well in the first stage, but may not in the rest of stages for the following
reason. More large tiles in these stages increase the difficulty of playing the game, and
therefore the feature weights cannot accurately reflect the expected scores with the
difficulty. Thus, using another set of feature weights in the next stage makes it more
likely for the feature weights to reflect the expected scores. In next subsection, the
observation is justified in the experiments with significant improvements for 2048.
3.3
Experiments for MS-TD Learning
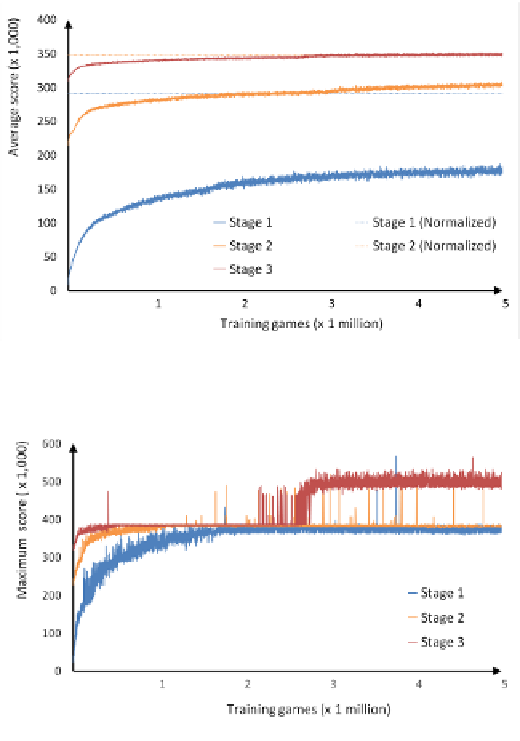
In the experiment for MS-TD learning, 5 million training games was run in each stage,
and average and maximum scores are sampled every 1000 games.
Fig. 7.
Average scores in MS-TD learning
Fig. 8.
Maximum scores in MS-TD learning
Search WWH ::

Custom Search