Information Technology Reference
In-Depth Information
where
,
is the reward for action
on state
, and
,,
is the
probability of turning into state
after taking action
on state
.
3.
Evaluate states after an action. This method is to evaluate the value function
′
on state
′
, a state after an action, also called
after-states
in [17]. As shown in Fig.
3, this method evaluates
′
and
′
.The agent chooses a move with the
highest expected score on
′
, as the following formula.
,
′
.
(6)
In [17], their experiments showed that the third method clearly outperformed the
other two. Therefore, in this paper, we only consider this method, evaluating after-
states. For simplicity, states refers to after-states in the rest of this paper.
2.4
N-Tuple Network
In [17], they also proposed to use
N-tuple network
for TD learning of 2048. An n-tuple
network consists of
-tuples, where
is the size of the
-th tuple. As shown in
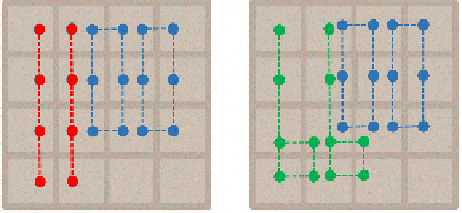
Fig. 4, one 4-tuple covers four cells marked in red rectangular and one 6-tuple covers
six cell marked in blue rectangular. Each tuple contributes a large number of features,
each for one distinct occurrence of tiles on the covered cells. For example, the leftmost
4-tuple in Fig. 4 (a) includes 16
4
features, assuming that a cell has 16 occurrences,
empty or 2-tile to 2
15
-tile.
(a) (b)
Fig. 4.
(a) Tuples used in [17] and (b) tuples used in this paper
Based on TD learning, the expected score
is a linear summation of feature
weights for all occurred features. For each tuple, since there is one and only one feature
occurrence, we can simply use a lookup table to locate the feature weight. Thus, if the
n-tuple network includes
different tuples, we need
lookups.
In [17], they used the tuples shown in Fig. 4 (a) as well as all of their rotated and
mirrored tuples. All the rotated and mirrored tuples can share the same feature weights.
Thus, the total number of features is roughly 2x2
16
+2x2
24
, about 32 million.
Their experiments showed that the tuples shown in Fig. 4 (a) outperformed all other
n-tuple networks used in their experiments. The experimental results claimed in [17]
include an average score of 100178 and a maximum score of 261526.

Search WWH ::

Custom Search