Information Technology Reference
In-Depth Information
predict test data
ġ
y
ġ
Stop
criteria
ġ
Result
ġ
predict U
T
ġ
training
ġ
L
S
ġ
M
S
/M
C
ġ
n
ġ
Result
ġ
Selection
ġ
Finish
ġ
U
T
ġ
L
T
ġ
M
T
ġ
Result
ġ
training
ġ
predict U
T
ġ
Human annotation
ġ
¨/
T
ġ
Fig. 1.
Flowchart of our QBC-based active learning
Another issue in active learning is determining suitable stop criteria. Here
we assume that the F-measure of the current combined model (
M
C
)is
S
2
,and
the previous combined model's F-measure is
S
1
,when
S
2
−
S
1
is lower than a
threshold
t
, the active learning process stops.
4 Experiments
4.1 Datasets
We compile three annotated datasets: 10,000 restaurant review sentences
annotated by two experts.
We conduct domain adaptation experiments on all C
2
domain pairs. In each
experiment, a dataset is chosen as the dataset of the source domain (denoted
as
D
S
), and the other dataset is the dataset of the target domain (denoted as
D
T
). We use all of the 10,000 sentences from
D
S
for training and randomly
select 3,000 sentences from
D
T
30 times for testing. The remaining 7,000
D
T
sentences are treated as the selection pool for active learning.
4.2 Evaluation Metrics
The results are given as F-measures and defined as 2
PR/
(
P
+
R
), where
P
de-
notes the precision of opinion word mentions and
R
denotes the recall of opinion
word mentions. We sum the scores for all 30 tests, and calculate the averages for
performance comparison. The results are reported as the mean precision (
P
),
recall (
R
), and F-measure (
F
) of thirty datasets.




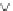

































Search WWH ::

Custom Search