Information Technology Reference
In-Depth Information
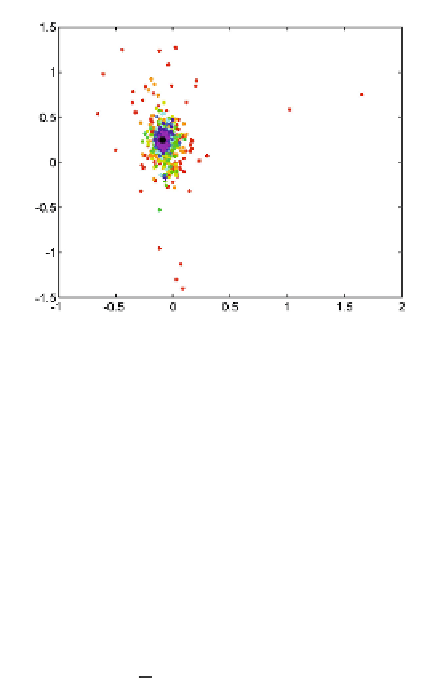
Fig. 1.
Data distribution of projecting the different portion of data into 2D space
Here we reformulate semi-supervised dimension reduction which inhert the su-
pervised KSIR.
K
denotes the kernelized entire dataset and
K
denotes kernelized
labelled dataset. The goal becomes to solve the following generality eigenvalue
problem:
ʣ
E
(
K|Y
J
)
ʲ
=
ʻʣ
K
ʲ.
(7)
And the between-class covariance will be
J
ʣ
E
(
K|Y
J
)
=
1
n
K
)
n
j
(
K
j
K
)(
K
j
−
−
(8)
j
=1
where
K
is the grand mean computed through the kernelized entire dataset,
including labelled and unlabelled data,
K
j
is the sample mean for the
j
th slice,
estimated by the kernelized labeled data of
j
th slice.
In the observation of solving eigenvalue decomposition problem, the effective
rank of the covariance matrix of kernel data is quite low, so we take only top
J
1 components for KSIR computing, where the
J
is the number of classes.
This restricts its use in binary classification problems since only one-direction
can be obtained, which will drop much information in the
e.d.r.
subspace. Basic
clustering approach is applied to force training data separate to more classes for
finding the KSIR directions. With believe of high dimension data can describe
the data more accurate, for the training data with labeled information in binary
classification, we use
K
-means to partition positive instances into two different
clusters for each class.Then, using those four classes as their new label for KSIR
to compute the
J
−
1 direction(we got 3 direction in this example). After getting
the direction, the data is put back to the original one and use the original label
information for SVM to classify. Thus, we can give more descriptive variables
for the classification purpose.
−
Search WWH ::

Custom Search