Information Technology Reference
In-Depth Information
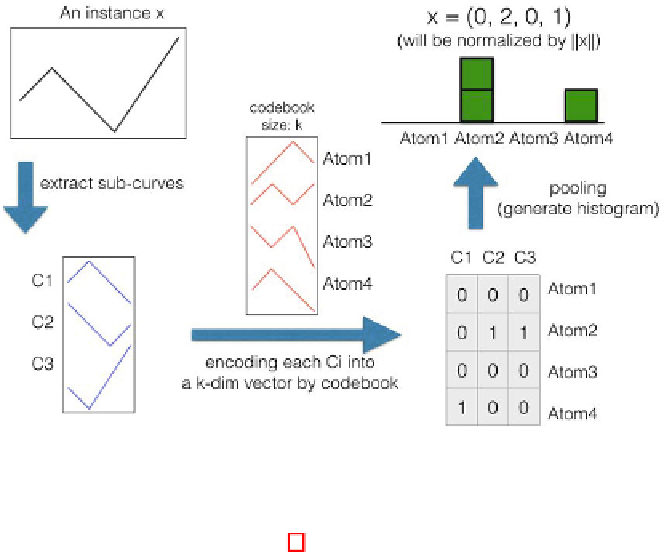
Fig. 3.
The procedure of encoding an time series data instance
time series data instance (see Fig 3). First, we also extract
p
w
+ 1 subse-
quences (i.e.,
c
1
,
c
2
, ...,
c
p−w
+1
) from each time series data instance by the same
sliding window. To aggregate the information of these collected subsequences,
we encode each subsequence into a
d
-dimensional vector
h
=(
h
1
,h
2
, ..., h
d
).
More specifically, we map each subsequence to the closest centroid and encode
the corresponding dimension with one. That is, by given a subsequences
c
,the
formal definition of the encoding vector
h
is expressed as follows:
h
i
=
1if
c
is closest to
i
th centroid
,
−
(1)
0
.
For example, if a subsequence is closest to the 3th centroid with 5 centroids
which concluded by the clustering algorithm, we will encode the subsequence as
(0,0,1,0,0).
Once we have encoded all the subsequences within a time series data instance
with
p
w
+ 1 vectors, we summarize the information by computing the his-
togram of the
d
features (codewords). As shown in Fig 3, the original time series
data instance
x
can be extracted with three subsequences. By encoding each
subsequence into a 4-dimensional vectors, we can compute the histogram for
the codewords. By aggregating the encoding vectors with sum, the original time
series data instance is represented as (0, 2, 0, 1). While encoding all the time
series data instances, the standard learning models can be applied for further
analysis, such as classification. It is also worth noting that the normalization will
be applied for a more robust representation.
−
Search WWH ::

Custom Search