Biomedical Engineering Reference
In-Depth Information
Fig. 4.
A 3 Layer MLP
If the output q = (q
1
; : : : ; q
n
) for a given input p = (p
1
; : : : ; p
r
) is
known, then the pair (p; q) is known as a training pattern because the
pair can be used to estimate the weights w
kl
and
jk
necessary for the
stimulus p to predict a classification of q. The energy function for a
collection
p
1
; q
1
; : : : ; (p
r
; q
r
) of training patterns is dened
X
t
E =
1
2
2
yq
i
i=1
where y = (y
1
; : : : ; y
n
) and where the norm is dened by the corresponding
dot product. The network is trained to a collection of training patterns if
@E
@w
kl
@E
@
jk
= 0 and
= 0
at the inputs p
i
for all l = 1 : : : r; k = 1 : : : m; and j = 1 : : : n: Because these
equations cannot be solved directly, a gradient-following method called the
backpropagation algorithm is used instead. The algorithm is based on the
observation
0
= (1) ;
which can be used to simplify @E=@
jk
and @E=@w
kl
. In particular,
for each training pattern (p
i
; q
i
), a 3-layer MLP rst calculates y as
the output to p
i
; which is the feedforward
step.
The weights
jk
are
subsequently adjusted using
jk
!
jk
+
j
k
where
k
= (w
k
x
k
), where > 0 is a xed parameter called the
learning rate, and where
q
j
y
j
j
= y
j
(1y
j
)
:





























































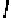




















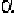





Search WWH ::

Custom Search