Digital Signal Processing Reference
In-Depth Information
which follows an information data block of length 18 leading to a subblock of 23 sym-
bols. This subblock was repeated over a record length of 418 symbols with a total of
16 subblocks. Thus, the training-to-information bit and power ratios are both 0.3 (the
amplitude of the single nonzero training bit was picked to achieve this power ratio).
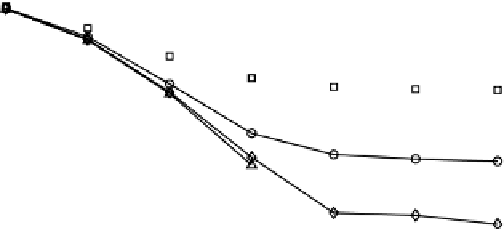
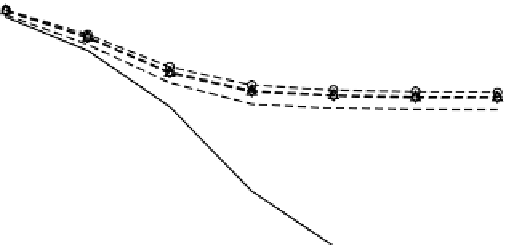
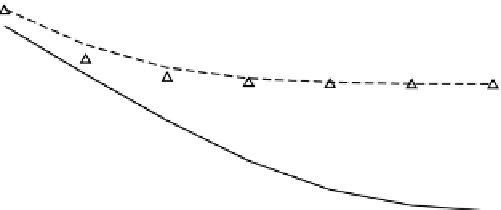
The results of our simulation averaged over five hundred runs are shown in Figures 2.6,
superimposed training schemes (denoted as SI in the figures), including the first-order
Viterbi detector: K = N = 1, L = 2, T = 420, T
s
= 25µs, TIR = 0.3, P = 7, f
d
= 100 Hz, 500 runs.
10
0
10
−1
10
−2
10
−3
SI&DPS: step1
SI&DPS: 1st iter.
SI&DPS: 2nd iter.
SI&DPS: 3rd iter.
SI&CE: step1
SI&CE: 1st iter.
SI&CE: 2nd iter.
SI&CE: 3rd iter.
TM&DPS
TM&CE
10
−4
10
−5
10
−6
0
5
10
15
20
25
30
SNR (dB)
FIgure 2.6
BER versus SNR for
f
d
= 100 Hz.
Viterbi Detector: K = N = 1, L = 2, T = 420, T
s
= 25µs, TIR = 0.3, P = 7, f
d
= 100 Hz, 500 runs.
−5
−10
−15
−20
SI&DPS: step1
SI&DPS: 1st iter.
SI&DPS: 2nd iter.
SI&DPS: 3rd iter.
SI&CE: step1
SI&CE: 1st iter.
SI&CE: 2nd iter.
SI&CE: 3rd iter.
TM&DPS
TM&CE
−25
−30
−35
−40
0
5
10
15
20
25
30
SNR (dB)
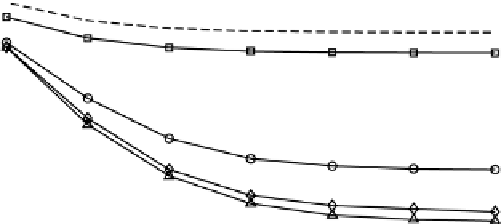
FIgure 2.7
MSE versus SNR for
f
d
= 100 Hz.








































Search WWH ::

Custom Search