Digital Signal Processing Reference
In-Depth Information
L
+= −
∂
∂
Jn
bn
bn
()
()
)
=
∑
1
(
bn
(
1
)
bn
()
µ
=
()
+
2
µ
ffaxnb
c
′
()
+
wen
()
,
(5.10)
ki
ki
ki
ki
ki
k
ki
lkl
ki
l
where μ is a small positive constant.
The adaptive system is initialized with a set of small random-weight values. The
learning curve is defined as the evolution of the mean squared error (MSE) during the
learning process. In modeling fixed (i.e., static) MIMO systems, the MSE error starts to
decrease until the system reaches a steady state and only slight changes in the weights
are observed. In that case, the learning process may be stopped. However, if the MIMO
system is time varying, then the learning process should be maintained in order to keep
tracking the time-varying parameters.
We have chosen to compare our results to the classical multilayer perceptron (MLP)
[2]. The MLP is composed of
M
inputs, a number of nonlinear neurons in the first layer,
followed by
L
linear combiners (Figure 5.4).
The MLP is trained using the backpropagation algorithm [2, 3]. It allows a black-
box modeling [8, 9, 13] of the unknown MIMO system, i.e., the modeling of the overall
nonlinear MIMO input-output transfer function, without being able to characterize the
different parts of the unknown system (i.e., the memoryless nonlinearities and the com-
bining matrix
H
).
For a fair comparison between the MLP structure and the proposed NN block struc-
ture, we will take the same total number of neurons in each scheme. Therefore, for the
block structure, if we denote the number of neurons in each block by
N
, then the total
number of neurons will be equal to
MN
. This structure will be compared to an MLP
with
MN
neurons.
Table 5.1
compares the computational complexity of each algorithm:
x
1
(
n
)
∑
s
1
(
n
)
s
2
(
n
)
∑
x
2
(
n
)
s
L
(
n
)
∑
x
M
(
n
)
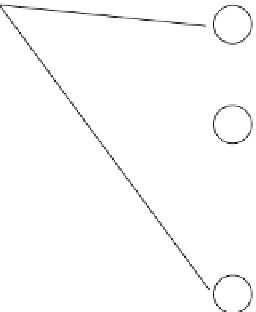
FIgure 5.4
MLP structure.

































Search WWH ::

Custom Search