Game Development Reference
In-Depth Information
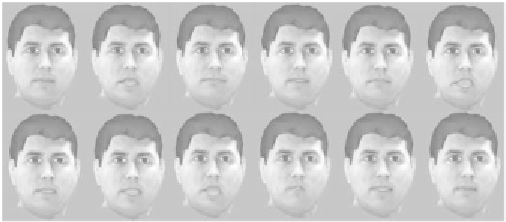
Figure 11. Typical animation frames. Temporal order: from left to right;
from top to bottom.
The whole animation procedure contains three steps. First, we extract audio
features from the input speech. Then, we use the trained neural networks to map
the audio features to the visual features (i.e., MUPs). Finally, we use the
estimated MUPs to animate a personalized 3D face model in iFACE. Figure 11
shows a typical animation sequence for the sentence in Figure 10.
Our real-time speech-driven animation can be used in real-time two-way
communication scenarios such as video-phone and virtual environments (Leung
et al., 2000). On the other hand, existing off-line speech-driven animation, e.g.,
Brand (1999), can be used in one-way communication scenarios, such as
broadcasting and advertising. Our approach deals with the mapping of both
vowels and consonants, thus it is more accurate than real-time approaches with
only vowel-mapping (Morishima & Harashima, 1991; Goto, Kshirsagar &
Thalmann, 2001). Compared to real-time approaches using only one neural
network for all audio features (Massaro et al., 1999; Lavagetto, 1995), our local
ANN mapping (i.e., one neural network for each audio feature cluster) is more
efficient because each ANN is much simpler. Therefore, it can be trained with
much less effort for a certain set of training data. More generally, speech-driven
animation can be used in speech and language education (Cole et al., 1999), as
a speech understanding aid for noisy environments and hard-of-hearing people
and as a rehabilitation tool for facial motion disorders.
Human Emotion Perception Study
The synthetic talking face can be evaluated by human perception study. Here,
we describe our experiments which compare the influence of the synthetic
talking face on human emotion perception with that of the real face. We did
similar experiments for 2D MU-based speech-driven animation (Hong, Wen &

Search WWH ::

Custom Search