Game Development Reference
In-Depth Information
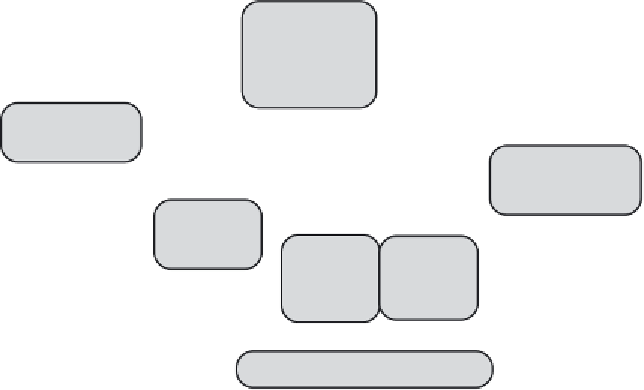
Figure 1. The machine learning based framework for facial deformation
modeling, facial motion analysis and synthesis.
Facial
movement video
MU-based
facial motion
analysis
MU-based
facial motion
analysis
Face image
sequence
Motion capture data
Speech
stream
MUP
sequence
Learn Motion
Units
Learn Motion
Units
Train audio-
visual mapping
Train audio-
visual mapping
Text
New speech
stre
a
m
Motion
Units:
holistic &
parts_based
Adapt
MU
Adapt
MU
Convert
text to
MUP
Convert
speech to
MUP
Convert
speech
to MUP
Convert
text to
MUP
Real-time
speech to
MUP
Mapping
MU-based face animation
MU-based face animation
Graphic face animation sequence with texture
3D facial motion capture data a
compact
set of
Motion Units
(MUs), which are
chosen as the quantitative visual representation of facial deformation. Then,
arbitrary facial deformation can be approximated by a linear combination of
MUs, weighted by coefficients called
Motion Unit Parameters
(MUPs). Based
on facial feature points and a Radial Basis Function (RBF) based interpolation,
the MUs can be adapted to new face geometry and different face mesh topology.
MU representation is used in both facial motion analysis and synthesis. Within
the framework, face animation is done by adjusting the MUPs. For facial motion
tracking, the linear space spanned by MUs is used to constrain low-level 2D
motion estimation. As a result, more robust tracking can be achieved. We also
utilize MUs to learn the correlation between speech and facial motion. A real-
time audio-to-visual mapping is learned using an Artificial Neural Network
(ANN) from an audio-visual database. Experimental results show that our
framework achieved natural face animation and robust non-rigid tracking.

















































































Search WWH ::

Custom Search