Game Development Reference
In-Depth Information
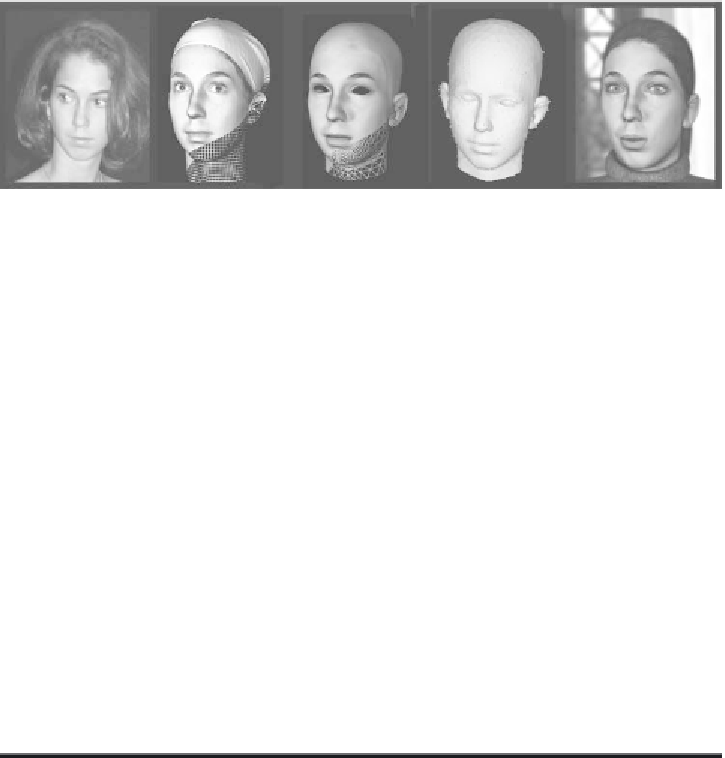
Figure 1. The workflow of our system: (a) An original face is (b) captured,
(c) re-meshed, (d) analyzed and integrated for (e) an animation.
narrowing the gap between modeling and animation. From measured 3D
face deformations around the mouth area, typical motions are extracted for
different “visemes”. Visemes are the basic motion patterns observed for
speech and are comparable to the phonemes of auditory speech. The
visemes are studied with sufficient detail to also cover natural variations
and differences between individuals. Furthermore, the transition between
visemes is analyzed in terms of co-articulation effects, i.e., the visual
blending of visemes as required for fluent, natural speech. The work
presented in this chapter also encompasses the animation of faces for
which no visemes have been observed and extracted. The “transplantation”
of visemes to novel faces for which no viseme data have been recorded and
for which only a static 3D model is available allows for the animation of
faces without an extensive learning procedure for each individual.
Introduction
Realistic face animation for speech still poses a number of challenges, especially
when we want to automate it to a large degree. Faces are the focus of attention
for an audience, and the slightest deviation from normal faces and face dynamics
is noticed.
There are several factors that make facial animation so elusive. First, the human
face is an extremely complex geometric form. Secondly, the face exhibits
countless tiny creases and wrinkles, as well as subtle variations in color and
texture, all of which are crucial for our comprehension and appreciation of facial
Search WWH ::

Custom Search